
This post provides an introduction to “word embeddings” or “word vectors”. Word embeddings are real-number vectors that represent words from a vocabulary, and have broad applications in the area of natural language processing (NLP).
If you have not tried using word embeddings in your sentiment, text classification, or other NLP tasks, it’s quite likely that you can increase your model accuracy significantly through their introduction. Word embeddings allow you to implicitly include external information from the world into your language understanding models.
The contents of this post were originally presented at the Python Pycon Dublin conference in 2017, and at the Dublin Chatbot and Artificial Intelligence meet up in December 2017. At my work with EdgeTier, we use word embeddings extensively across our Arthur agent assistant technology, and in all of our analysis services for customer contact centres.
What are word embeddings and word vectors?
The core concept of word embeddings is that every word used in a language can be represented by a set of real numbers (a vector). Word embeddings are N-dimensional vectors that try to capture word-meaning and context in their values. Any set of numbers is a valid word vector, but to be useful, a set of word vectors for a vocabulary should capture the meaning of words, the relationship between words, and the context of different words as they are used naturally.
There’s a few key characteristics to a set of useful word embeddings:
- Every word has a unique word embedding (or “vector”), which is just a list of numbers for each word.
- The word embeddings are multidimensional; typically for a good model, embeddings are between 50 and 500 in length.
- For each word, the embedding captures the “meaning” of the word.
- Similar words end up with similar embedding values.
All of these points will become clear as we go through the following examples.
Simple Example of Word Embeddings
One-hot Encoding
The simplest example of a word embedding scheme is a one-hot encoding. In a one-hot encoding, or “1-of-N” encoding, the embedding space has the same number of dimensions as the number of words in the vocabulary; each word embedding is predominantly made up of zeros, with a “1” in the corresponding dimension for the word.
A simple one-hot word embedding for a small vocabulary of nine words is shown in the diagram below.
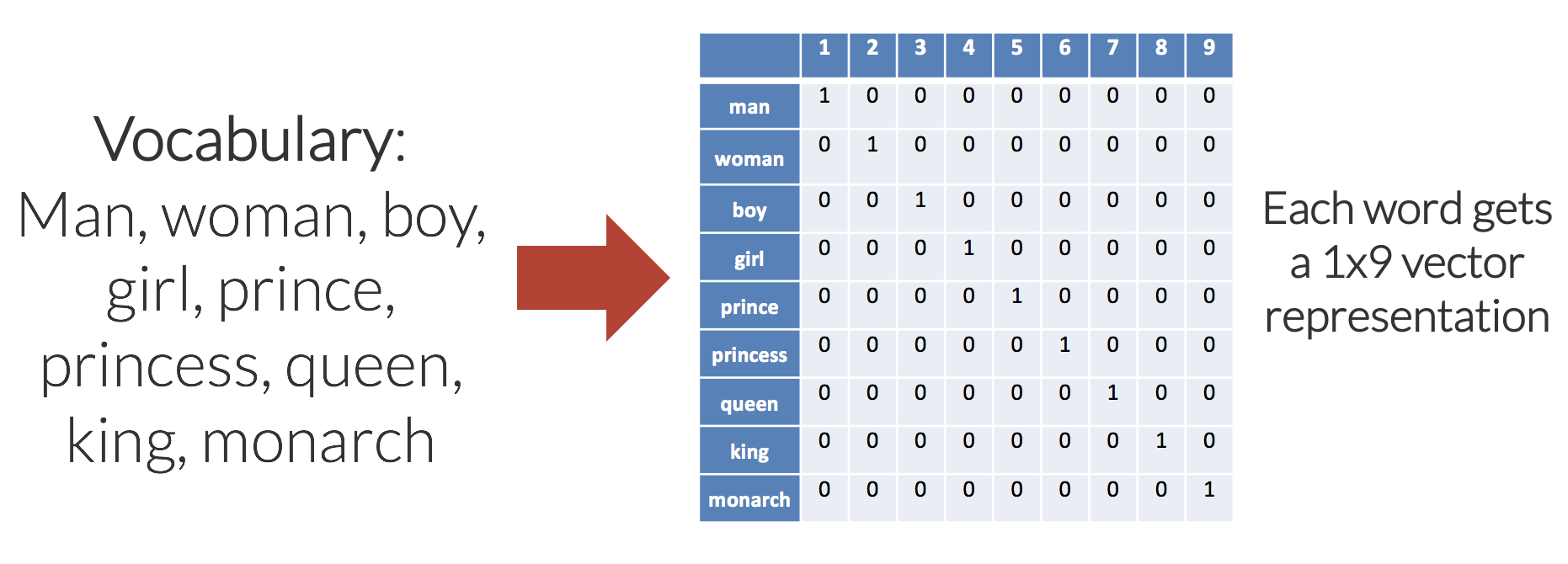
There are a few problems with the one-hot approach for encoding:
- The number of dimensions (columns in this case), increases linearly as we add words to the vocabulary. For a vocabulary of 50,000 words, each word is represented with 49,999 zeros, and a single “one” value in the correct location. As such, memory use is prohibitively large.
- The embedding matrix is very sparse, mainly made up of zeros.
- There is no shared information between words and no commonalities between similar words. All words are the same “distance” apart in the 9-dimensional (each word embedding is a [1×9] vector) embedding space.
Custom Encoding
What if we were to try to reduce the dimensionality of the encoding, i.e. use less numbers to represent each word? We could achieve this by manually choosing dimensions that make sense for the vocabulary that we are trying to represent. For this specific example, we could try dimensions labelled “femininity”, “youth”, and “royalty”, allowing decimal values between 0 and 1. Could you fill in valid values?
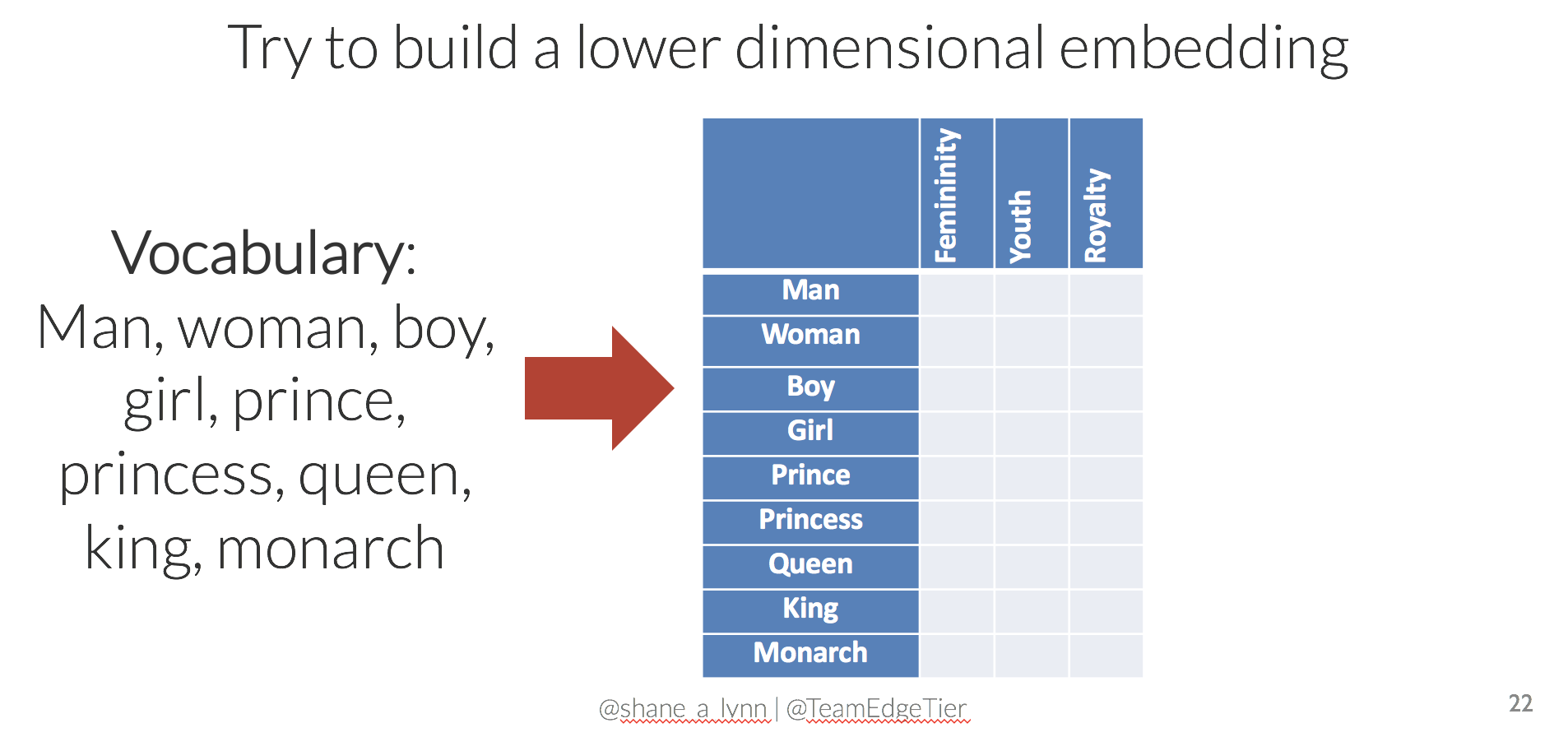
With only a few moments of thought, you may come up with something like the following to represent the 9 words in our vocabulary:
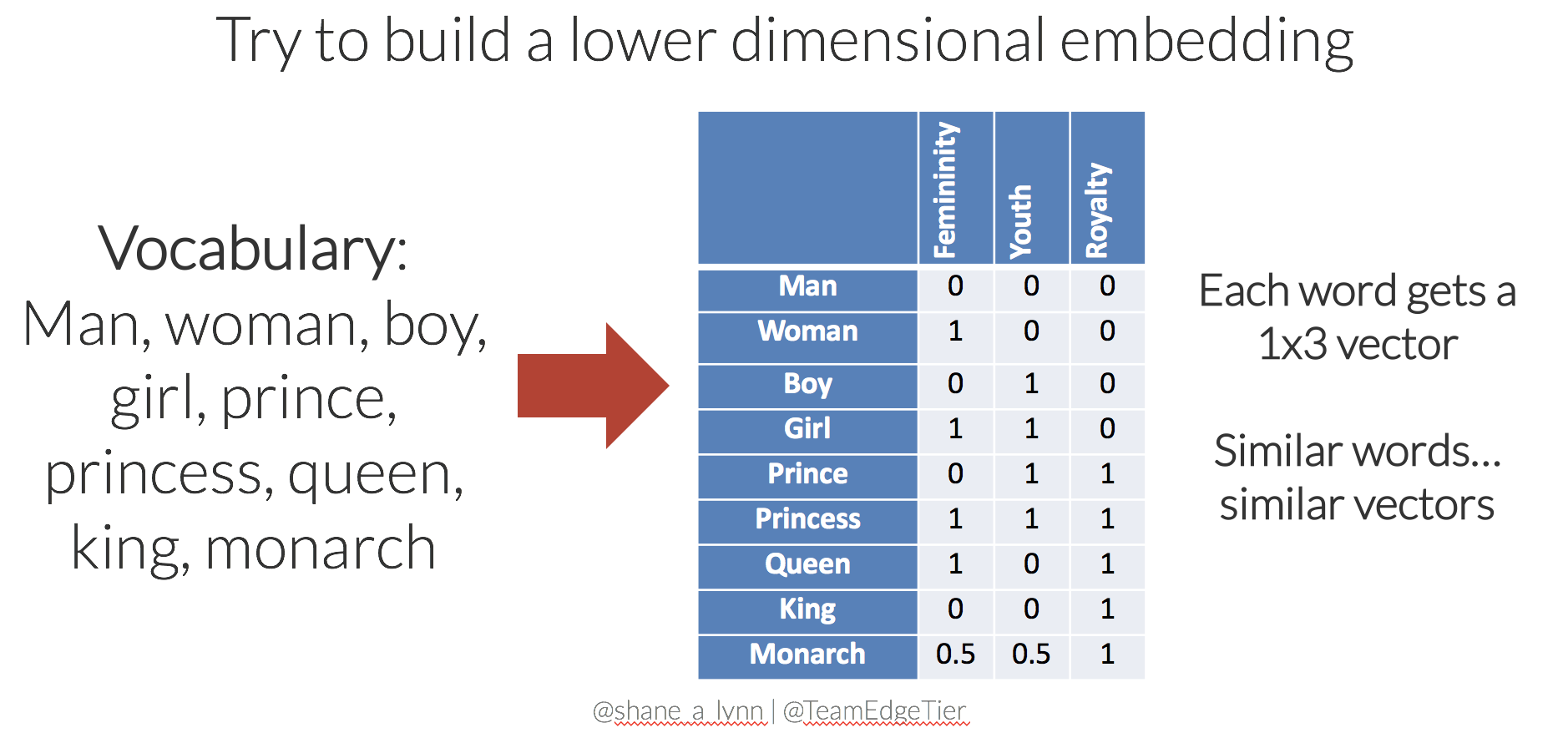
This new set of word embeddings has a few advantages:
- The set of embeddings is more efficient, each word is represented with a 3-dimensional vector.
- Similar words have similar vectors here. i.e. there’s a smaller distance between the embeddings for “girl” and “princess”, than from “girl” to “prince”. In this case, distance is defined by Euclidean distance.
- The embedding matrix is much less sparse (less empty space), and we could potentially add further words to the vocabulary without increasing the dimensionality. For instance, the word “child” might be represented with [0.5, 1, 0].
- Relationships between words are captured and maintained, e.g. the movement from king to queen, is the same as the movement from boy to girl, and could be represented by [+1, 0, 0].
Extending to larger vocabularies
The next step is to extend our simple 9-word example to the entire dictionary of words, or at least to the most commonly used words. Forming N-dimensional vectors that capture meaning in the same way that our simple example does, where similar words have similar embeddings and relationships between words are maintained, is not a simple task.
Manual assignment of vectors would be impossibly complex; typical word embedding models have hundreds of dimensions. and individual dimensions will not be directly interpretable. As such, various algorithms have been developed, some recently, that can take large bodies of text and create meaningful models. The most popular algorithms include the Word2Vec algorithm from Google, the GloVe algorithm from Stanford, and the fasttext algorithm from Facebook.
Before examining these techniques, we will discuss the properties of properly trained embeddings.
Word Embeddings Properties
A complete set of word embeddings exhibits amazing and useful properties, recognises words that are similar, and naturally captures the relationships between words as we use them.
Word Similarities / Synonyms
In the trained word embedding space, similar words converge to similar locations in N-D space. In the examples above, the words “car”, “vehicle”, and “van” will end up in a similar location in the embedding space, far away from non-related words like “moon”, “space”, “tree” etc.
“Similarity” in this sense can be defined as Euclidean distance (the actual distance between points in N-D space), or cosine similarity (the angle between two vectors in space).
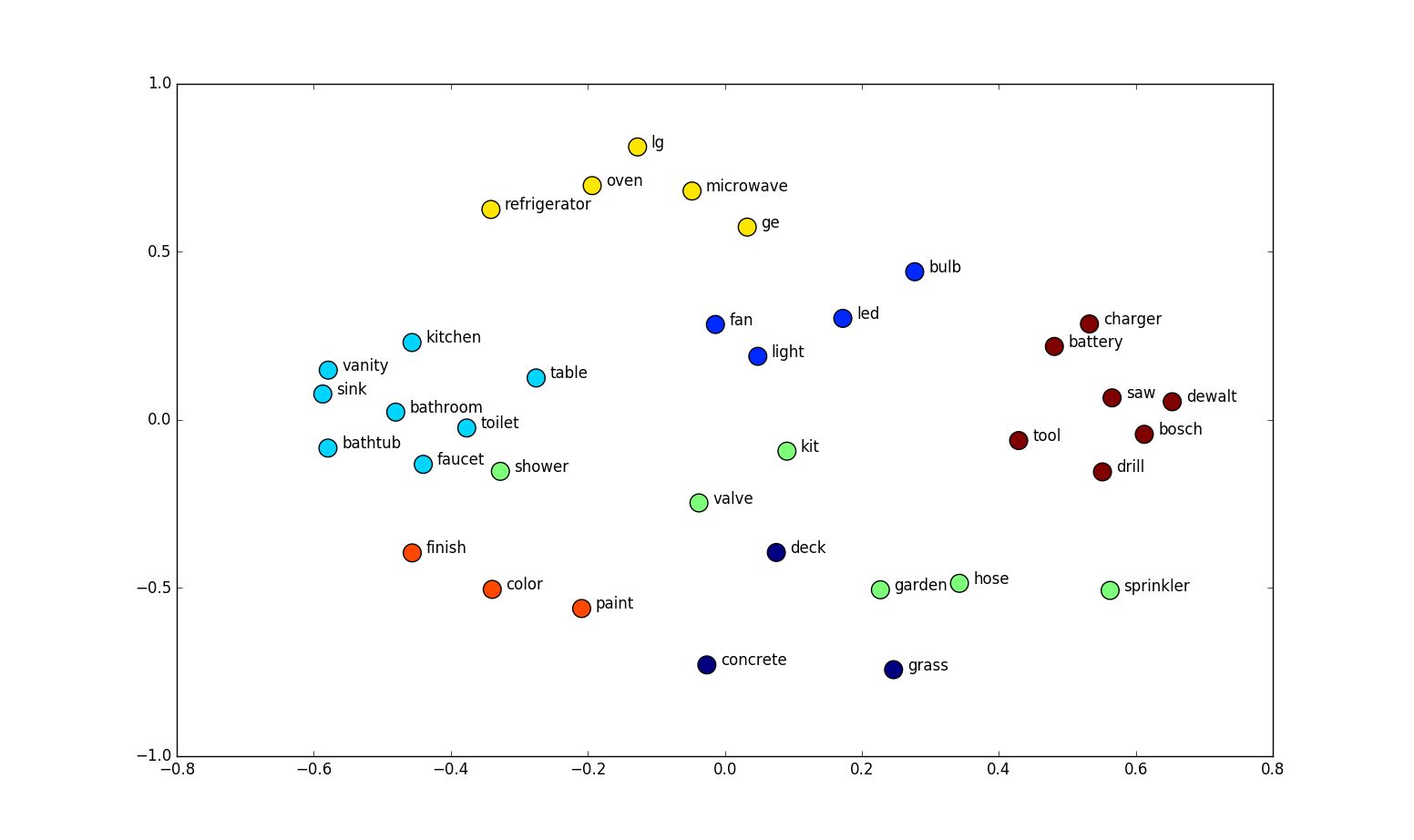

When loaded into Python, this property can be seen using Gensim, where the nearest words to a target word in the vector space can be extracted from a set of word embeddings easily.
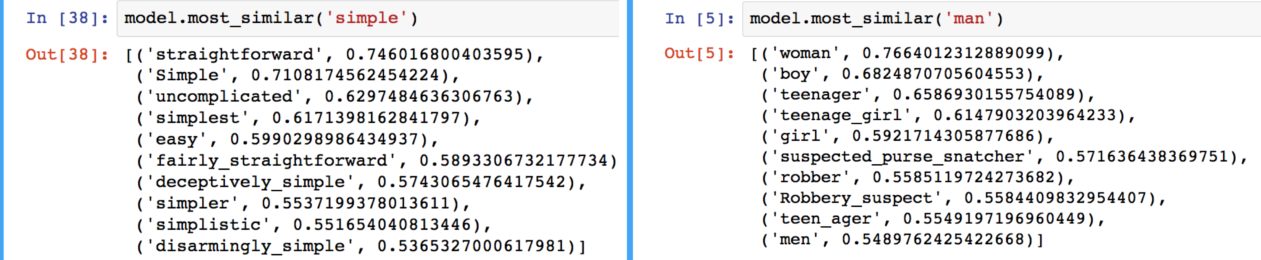
For machine learning applications, the similarity property of word embeddings allows applications to work with words that have not been seen during their training phase.
Instead of modelling using words alone, machine learning models instead use word vectors for predictive purposes. If words that were unseen during training, but known in the word embedding space, are presented to the model, the word vectors will continue to work well with the model, i.e. if a model is trained to recognise vectors for “car”, “van”, “jeep”, “automobile”, it will still behave well to the vector for “truck” due to the similarity of the vectors.
In this way, the use of word embeddings has implicitly injected additional information from the word embedding training set into the application. The ability to handle unseen terms (including misspellings) is a huge advantage of word embedding approaches over older popular TF-IDF / bag-of-words approaches.

Linguistic Relationships
A fascinating property of trained word embeddings is that the relationship between words in normal parlance is captured through linear relationships between vectors. For example, even in a large set of word embeddings, the transformation between the vector for “man” and “woman” is similar to the transformation between “king” and “queen”, “uncle” and “aunt”, “actor” and “actress”, generally defining a vector for “gender”.
In the original word embedding paper, relationships for “capital city of”, “major river in”, plurals, verb tense, and other interesting patterns have been documented. It’s important to understand that these relationships are not explicitly presented to the model during the training process, but are “discovered” from the use of language in the training dataset.

Another example of a relationship might include the move from male to female, or from past tense to future tense.
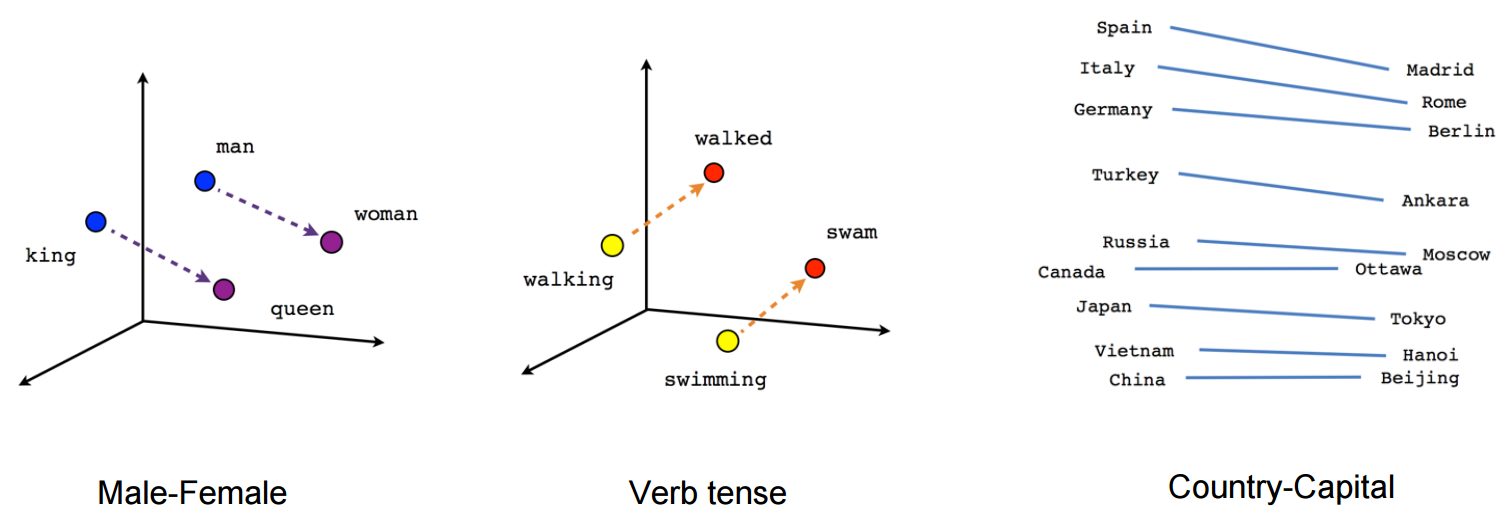
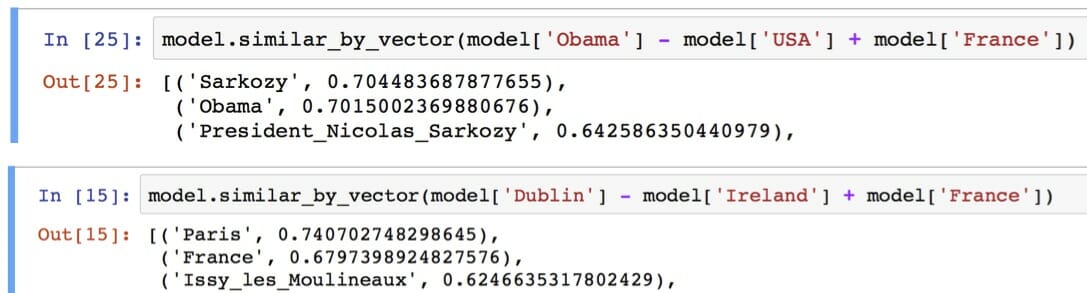
These linear relationships between words in the embedding space lend themselves to unusual word algebra, allowing words to be added and subtracted, and the results actually making sense. For instance, in a well defined word embedding model, calculations such as (where [[x]] denotes the vector for the word ‘x’)
[[king]] – [[man]] + [[woman]] = [[queen]]
[[Paris]] – [[France]] + [[Germany]] = [[Berlin]]
will actually work out!
Word Embedding Training Algorithms
Word Context
When training word embeddings for a large vocabulary, the focus is to optimise the embeddings such that the core meanings and the relationships between words is maintained. This idea was first captured by John Rupert Firth, an English linguist working on language patterns in the 1950s, who said:
“You shall know a word by the company it keeps” – Firth, J.R. (1957)
Firth was referring to the principal that the meaning of a word is somewhat captured by its use with other words, that the surrounding words (context) for any word are useful to capture the meaning of that word.
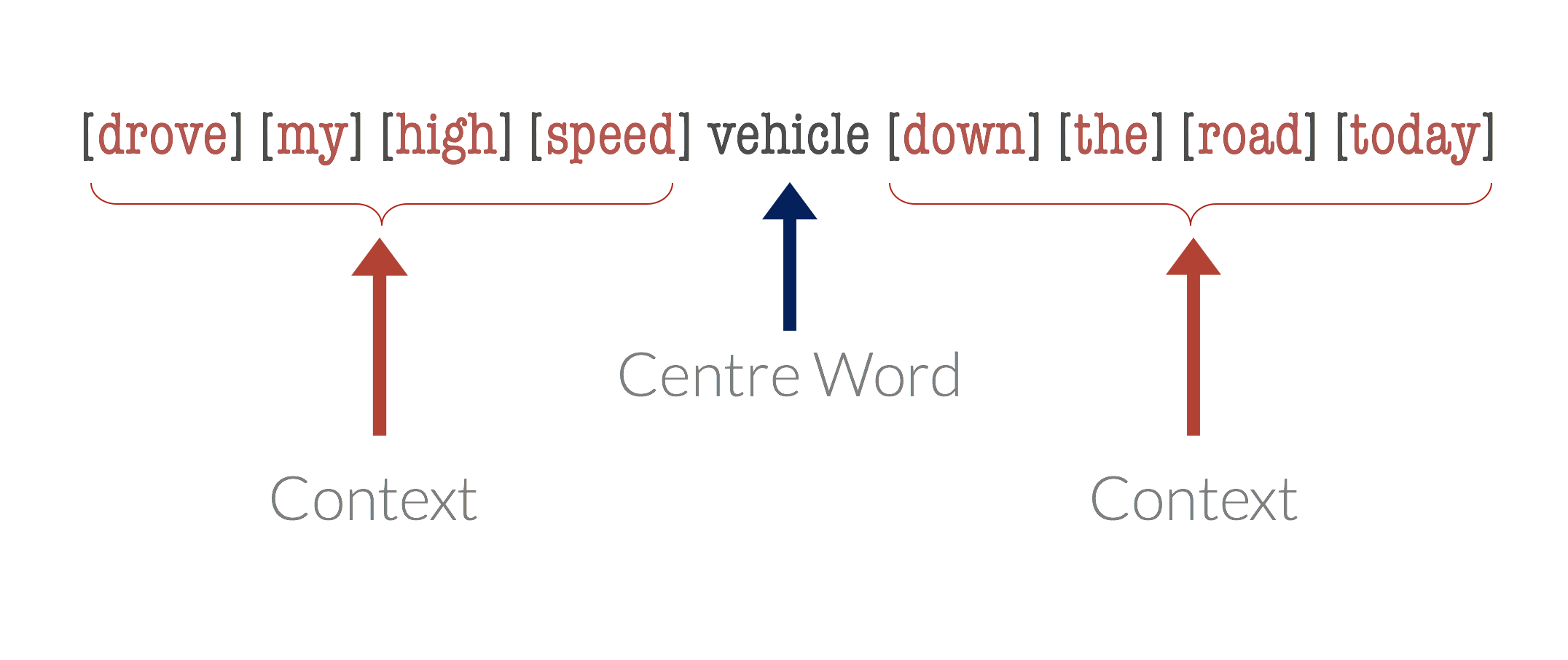
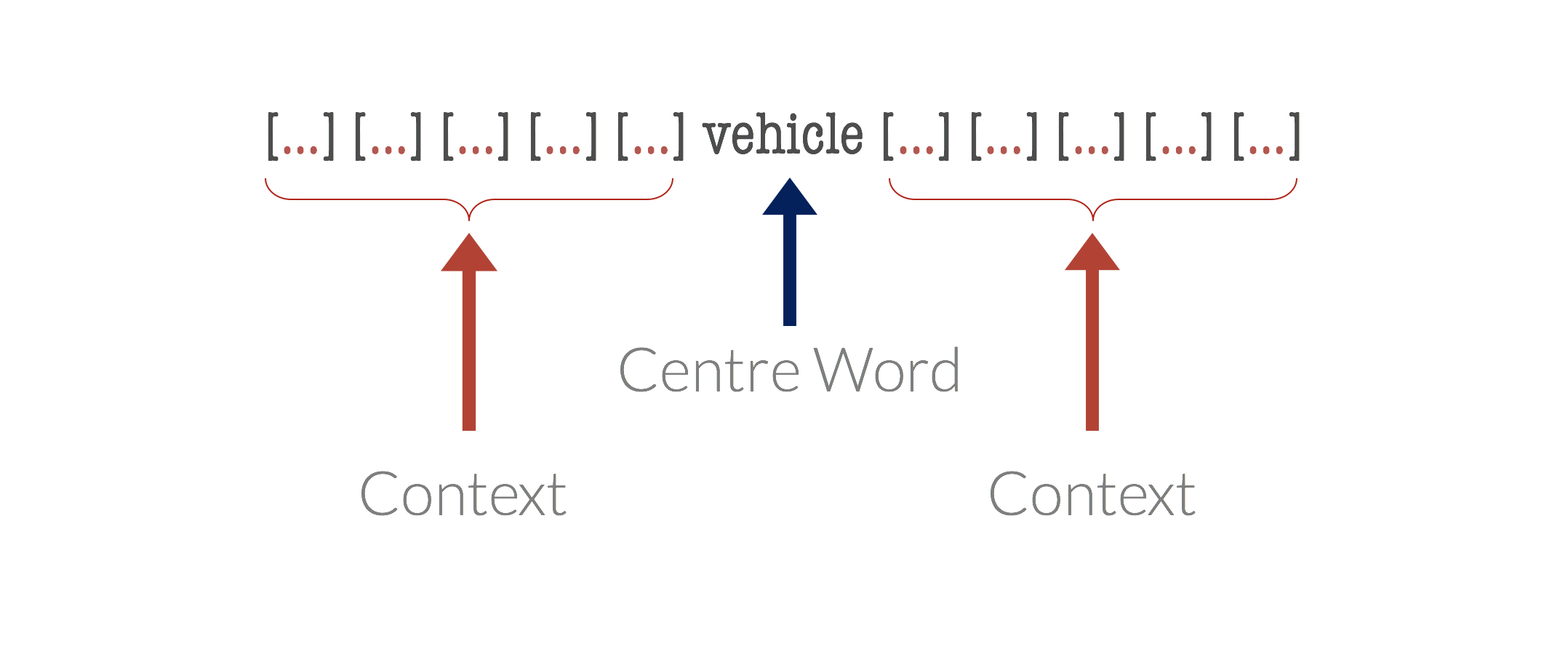
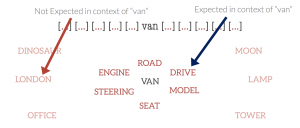
Suppose we take a word, termed the centre word, and then look at “typical” words that may surround it in common language use. The diagrams below show probable context words for specific centre words. In this example, the context words for “van” are supposed to be “tyre”, “road”, “travel” etc. The context words for a similar word to van, “car” are expected to be similar also. Conversely, the context words for a dissimilar word, like “moon”, would be expected to be completely different.
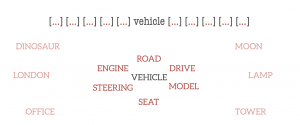
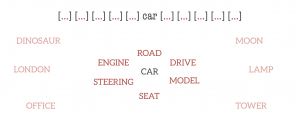

Word Vector Training
This principle of context words being similar for centre words of similar meaning is the basis of word embedding training algorithms.
There are two primary approaches to training word embedding models:
- Distributed Semantic Models: These models are based on the co-occurance / proximity of words together in large bodies of text. A co-occurance matrix is formed for a large text corpus (an NxN matrix with values denoting the probability that words occur closely together), and this matrix is factorised (using SVD / PCA / similar) to form a word vector matrix. Word embedding modelling tTechniques using this approach are known as “count approaches”.
- Neural Network Models: Neural network approaches are generally “predict approaches”, where models are constructed to predict the context words from a centre word, or the centre word from a set of context words.
Predict approaches tend to outperform count models in general, and some of the most popular word embedding algorithms, Skip Gram, Continuous Bag of Words (CBOW), and Word2Vec are all predict-type approaches.
To gain a fundamental understanding of how predict models work, consider the problem of predicting a set of context words from a single centre word. In this case, imagine predicting the context words “tyre”, “road”, “vehicle”, “door” from the centre word “car”. In the “Skip-Gram” approach, the centre word is represented as a single one-hot encoded vector, and presented to a neural network that is optimised to produce a vector with high values in place for the predicted context words – i.e values close to 1 for words – “tyre”, “vehicle”, “door” etc.
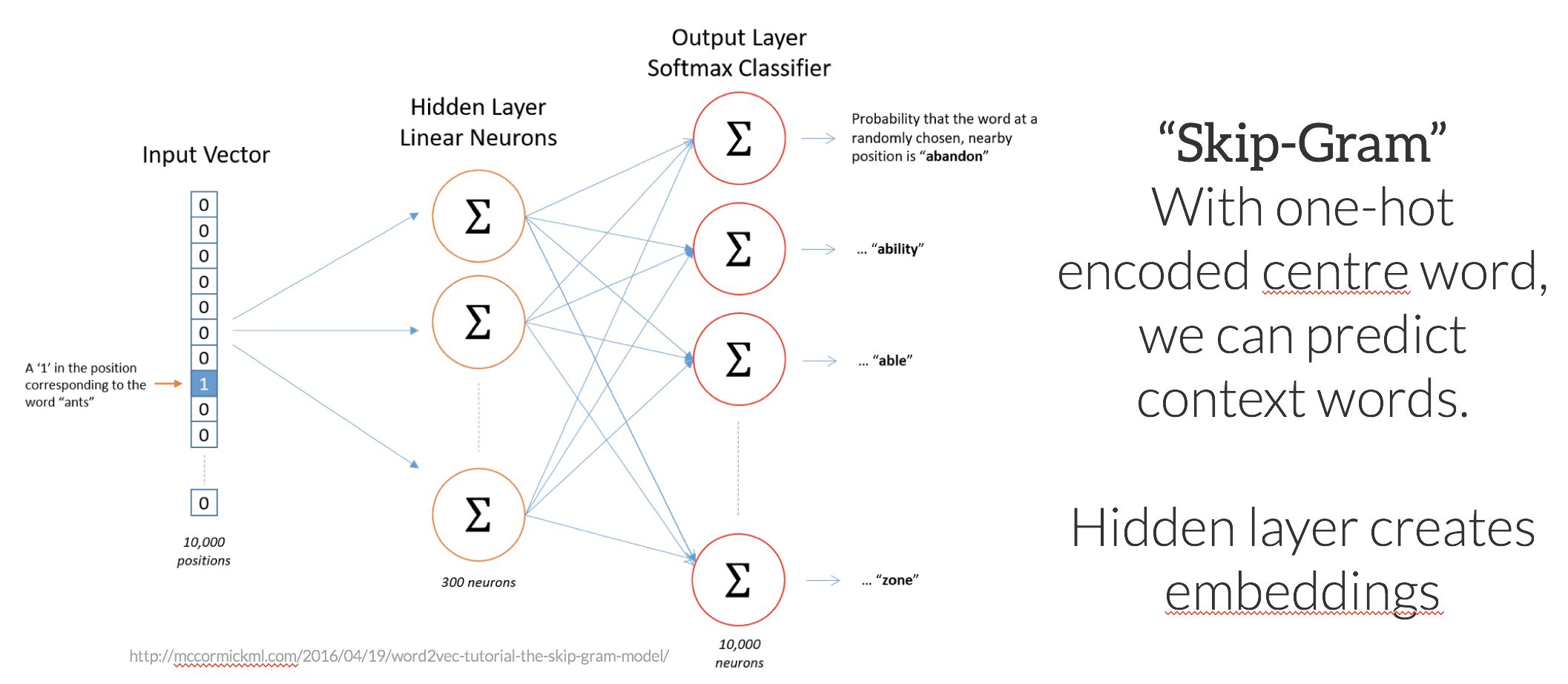
The internal layers of the neural network are linear weights, that can be represented as a matrix of size <(number of words in vocabulary) X (number of neurons (arbitrary))>. If you can imagine, if the output vector of the network for the words “car”, “vehicle”, and “van” need to be similar to correctly predict similar context words, the weights in the network for these words tend to converge to similar values. Ultimately, after convergence, the weights of the hidden network layer form the trained word embeddings.
A second approach, the Continuous Bag of Words (CBOW) approach, is the opposite structure – the centre word one-hot encoding is predicted from multiple context words.
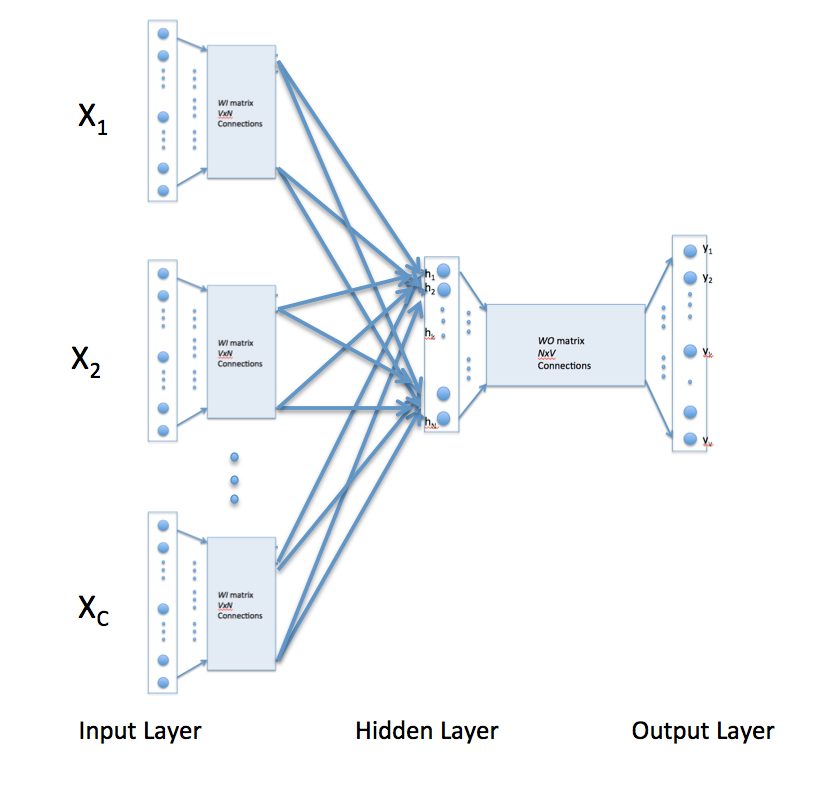
Popular Word Embedding Algorithms
One of the most popular training method “Word2Vec“, was developed by a team of researchers at Google, and, during training, actually uses CBOW and Skip-Gram techniques together. Other training methods have also been developed, including the “Global Vectors for Word Representations” (GloVe) from a team at Stanford, and the fasttext algorithm created by Facebook.

The quality of different word embedding models can be evaluated by examining the relationship between a known set of words. Mikolev et al (2013) developed an approach by which sets of vectors can be evaluated. Model accuracy and usefulness is sensitive to the training data used, the parameterisation of the training algorithm, the algorithm used, and the dimensionality of the model.
Using Word Embeddings in Python
There’s a few options for using word embeddings in your own work in Python. The two main libraries that I have used are Spacy, a high-performance natural language processing library, and Gensim, a library focussed on topic-modelling applications.
Pre-trained sets of word embeddings, created using the entire Wikipedia contents, or the history of Google News articles can be downloaded directly and integrated with your own models and systems. Alternatively, you can train your own models using Python with the Genesis library if you have data on which to base them – a custom model can outperform standard models for specific domains and vocabularies.
As a follow up to this blog post, I will post code examples and an introduction to using word-embeddings with Python separately.
Word Embeddings at EdgeTier
At our company, EdgeTier, we are developing an artificially-intelligent customer service agent-assistant tool, “Arthur“, that uses text classification and generation techniques to pre-write responses to customer queries for customer service teams.
Customer service queries are complex, freely written, multi-lingual, and contain multiple topics in one query. Our team uses word-embeddings in conjunction with deep neural-network models for highly accurate (>96%) topic and intent classification, allowing us to monitor trends in incoming queries, and to generate responses for the commonly occurring problems. Arthur integrates tightly with our clients CRM, internal APIs, and other systems to generate very specific, context-aware responses.
Overall, word embeddings lead to more accurate classification enabling 1000’s more queries per day to be classified, and as a result the Arthur systems leads to a 5x increase in agent efficiency – a huge boost!

Word Embedding Applications
Word embeddings have found use across the complete spectrum of NLP tasks.
- In conjunction with modelling techniques such as artificial neural networks, word embeddings have massively improved text classification accuracy in many domains including customer service, spam detection, document classification etc.
- Word embeddings are used to improve the quality of language translations, by aligning single-language word embeddings using a transformation matrix. See this example for an explanation attempting bilingual translation to four languages (English, German, Spanish, French)
- Word vectors are also used to improve the accuracy of document search and information retrieval applications, where search strings no longer require exact keyword searches and can be insensitive to spelling.
Further reading
If you want to drive these ideas home, and cement the learning in your head, it’s a good idea to spend an hour going through some of the videos and links below. Hopefully they make sense after reading the post!
- Coursera Deep Learning course video on Word Embeddings.
- Google Tensorflow Tutorial on Word Embeddings.
- Excellent break down for Skip-Gram algorithm.
- Chris McCormick – The Skip-Gram Model
- “The amazing power of word vectors” – Adrian Colyer
Thoroughly enjoyed reading ! Many Thanks
[…] post follows on from the previous “Get Busy with Word Embeddings” post, and provides code samples and methods for you to use and create Word Embeddings / Word […]
[…] covered in these couple of blog posts of useful to gain a quick overview of Word Vectors: ‘Get busy with Word Embeddings’ by Shane Lynn and ‘How to develop Word Embedding using Python’ by Jason Brownlee. This […]
[…] https://www.shanelynn.ie/get-busy-with-word-embeddings-introduction/ […]
nice way to explain
Simple and very clear presentation. Thank you very much !
Vow! Beautiful way of explaining word embeddings…. I am writing this reply even before reading the whole stuff as I could not wait to express my amazement at the way you easily explained this concept. Am sure you will continue to amaze as I go further down in the blog…
Thanks a ton for this…. I will share this URL with my students….
there is something strange in the picture of the python-code in which the most similar words to “simple” and “man” are displayed…
“Siimple” is obviously more similar to the word “simple” than straightforward, i mean it is the same word only written in Upper Case letters.
Also “Woman” can’t be more similiar to “man” than “Boy” or “men”.
Is it the failure of the unsupervised Learning ALgorithmen ?
[…] Figure 1: A 2-dimensional illustration of a word embedding space [source] […]
[…] by the Humboldt University of Berlin, Flair essentially neatly wraps up powerful NLP techniques and word embedding models to allow users to access state-of-the-art technology with a few simple commands. For those not […]
[…] https://www.shanelynn.ie/get-busy-with-word-embeddings-introduction/ […]
[…] Embedding illustration for given vocabulary (Source) […]
[…] Embedding illustration for given vocabulary (Source) […]
that was the best explanation I have ever seen .. thanks a lot