
Pandas Data Selection
There are multiple ways to select and index rows and columns from Pandas DataFrames. I find tutorials online focusing on advanced selections of row and column choices a little complex for my requirements, but mastering the Pandas iloc, loc, and ix selectors can actually be made quite simple.
Selection Options
There’s three main options to achieve the selection and indexing activities in Pandas, which can be confusing. The three selection cases and methods covered in this post are:
- Selecting data by row numbers (.iloc)
- Selecting data by label or by a conditional statement (.loc)
- Selecting in a hybrid approach (.ix) (now Deprecated in Pandas 0.20.1)
Data Setup
This blog post, inspired by other tutorials, describes selection activities with these operations. The tutorial is suited for the general data science situation where, typically I find myself:
- Each row in your data frame represents a data sample.
- Each column is a variable, and is usually named. I rarely select columns without their names.
- I need to quickly and often select relevant rows from the data frame for modelling and visualisation activities.
For the uninitiated, the Pandas library for Python provides high-performance, easy-to-use data structures and data analysis tools for handling tabular data in “series” and in “data frames”. It’s brilliant at making your data processing easier and I’ve written before about grouping and summarising data with Pandas.

Selection and Indexing Methods for Pandas DataFrames
For these explorations we’ll need some sample data – I downloaded the uk-500 sample data set from www.briandunning.com. This data contains artificial names, addresses, companies and phone numbers for fictitious UK characters. To follow along, you can download the .csv file here. Load the data as follows (the diagrams here come from a Jupyter notebook in the Anaconda Python install):
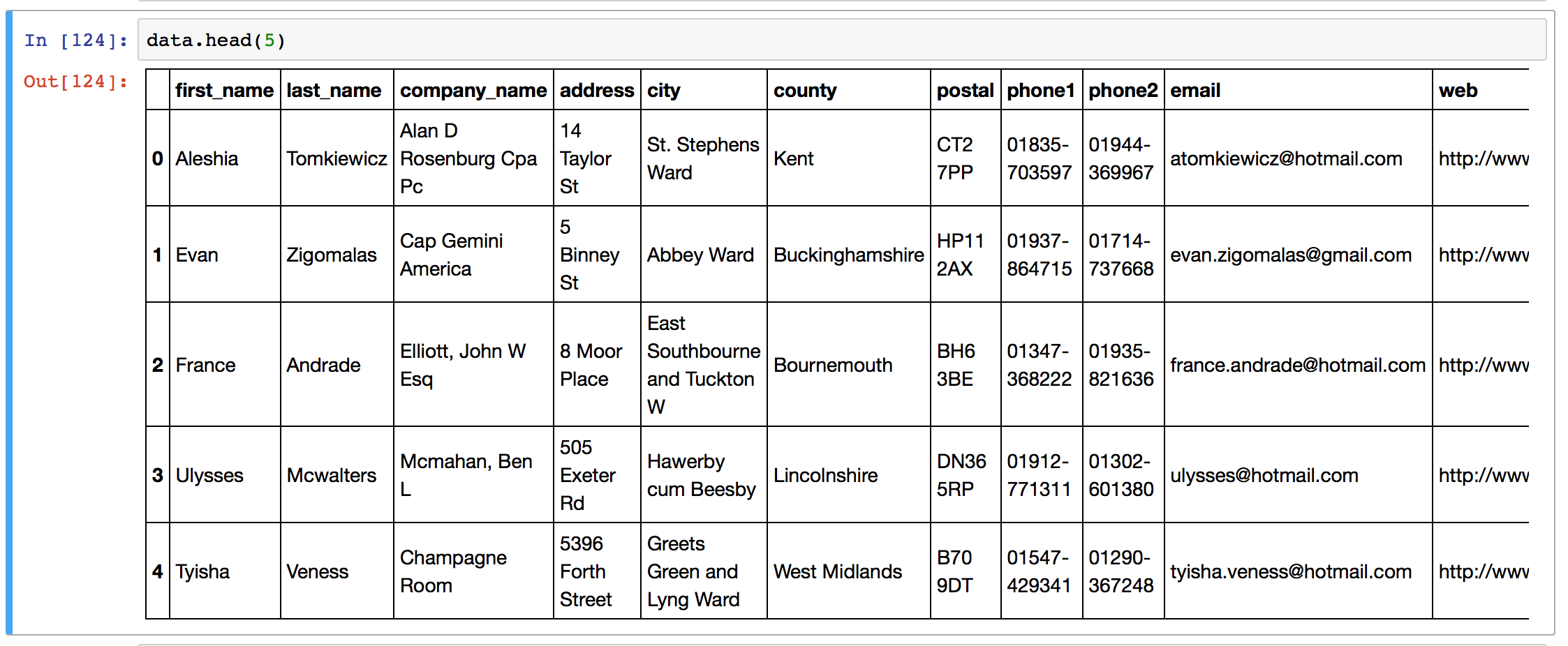
1. Pandas iloc data selection
The iloc indexer for Pandas Dataframe is used for integer-location based indexing / selection by position.
The iloc indexer syntax is data.iloc[<row selection>, <column selection>], which is sure to be a source of confusion for R users. “iloc” in pandas is used to select rows and columns by number, in the order that they appear in the data frame. You can imagine that each row has a row number from 0 to the total rows (data.shape[0]) and iloc[] allows selections based on these numbers. The same applies for columns (ranging from 0 to data.shape[1] )
There are two “arguments” to iloc – a row selector, and a column selector. For example:
Multiple columns and rows can be selected together using the .iloc indexer.
There’s two gotchas to remember when using iloc in this manner:
- Note that .iloc returns a Pandas Series when one row is selected, and a Pandas DataFrame when multiple rows are selected, or if any column in full is selected. To counter this, pass a single-valued list if you require DataFrame output.
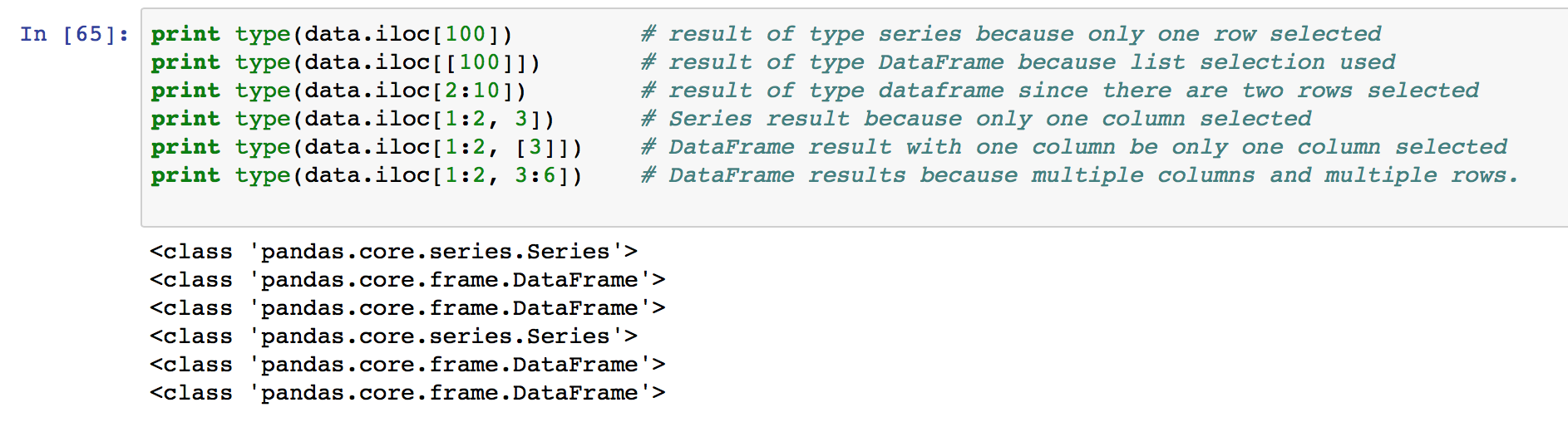
In practice, I rarely use the iloc indexer, unless I want the first ( .iloc[0] ) or the last ( .iloc[-1] ) row of the data frame.
2. Pandas loc data selection
The Pandas loc indexer can be used with DataFrames for two different use cases:
- a.) Selecting rows by label/index
- b.) Selecting rows with a boolean / conditional lookup
The loc indexer is used with the same syntax as iloc: data.loc[<row selection>, <column selection>] .
2a. Label-based / Index-based indexing using .loc
Selections using the loc method are based on the index of the data frame (if any). Where the index is set on a DataFrame, using <code>df.set_index()</code>, the .loc method directly selects based on index values of any rows. For example, setting the index of our test data frame to the persons “last_name”:
![Pandas Dataframe with index set using .set_index() for .loc[] explanation.](https://c8j9w8r3.rocketcdn.me/wp-content/uploads/2016/09/index_set_dataframe.png)
Now with the index set, we can directly select rows for different “last_name” values using .loc[<label>] – either singly, or in multiples. For example:
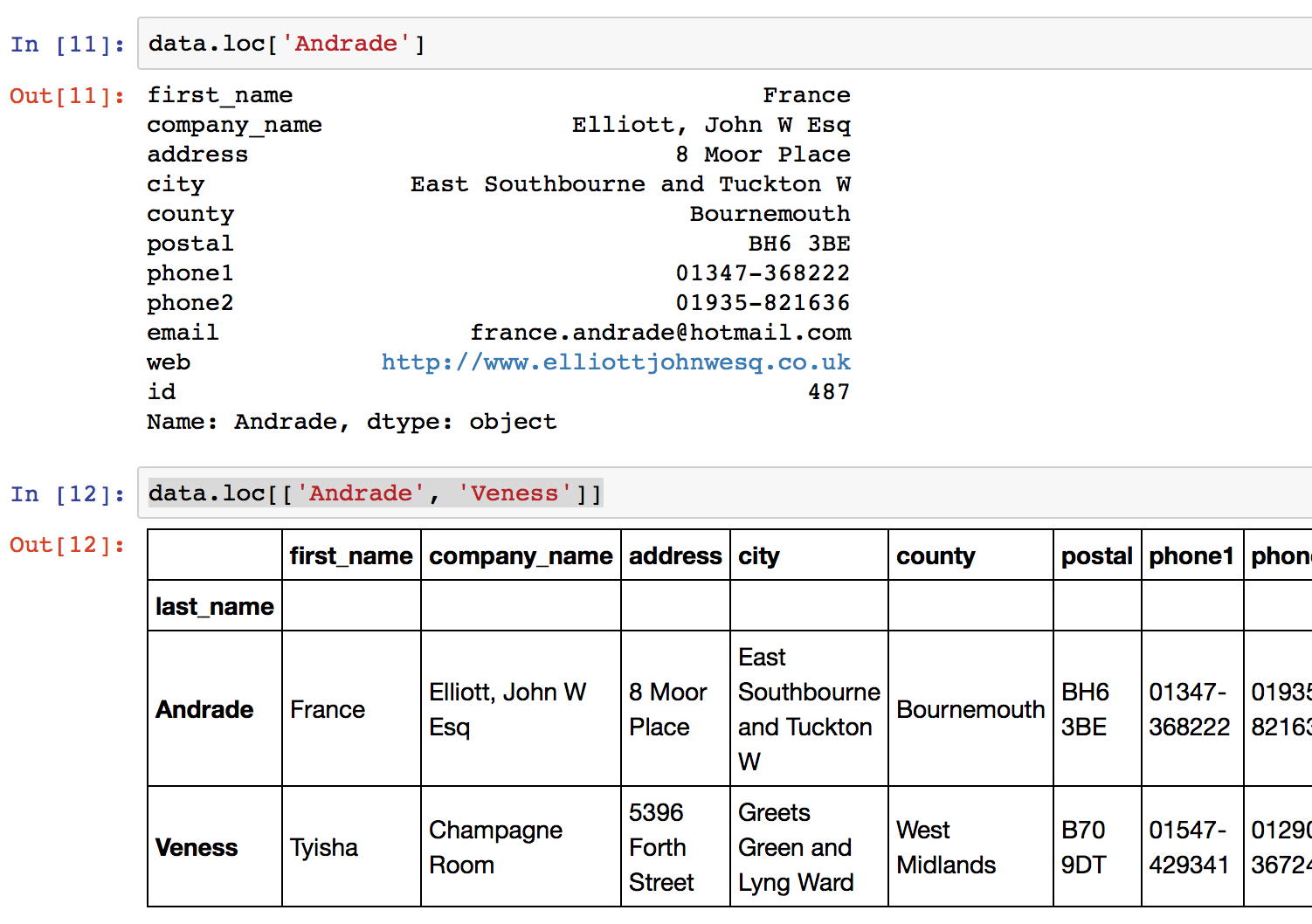
Select columns with .loc using the names of the columns. In most of my data work, typically I have named columns, and use these named selections.
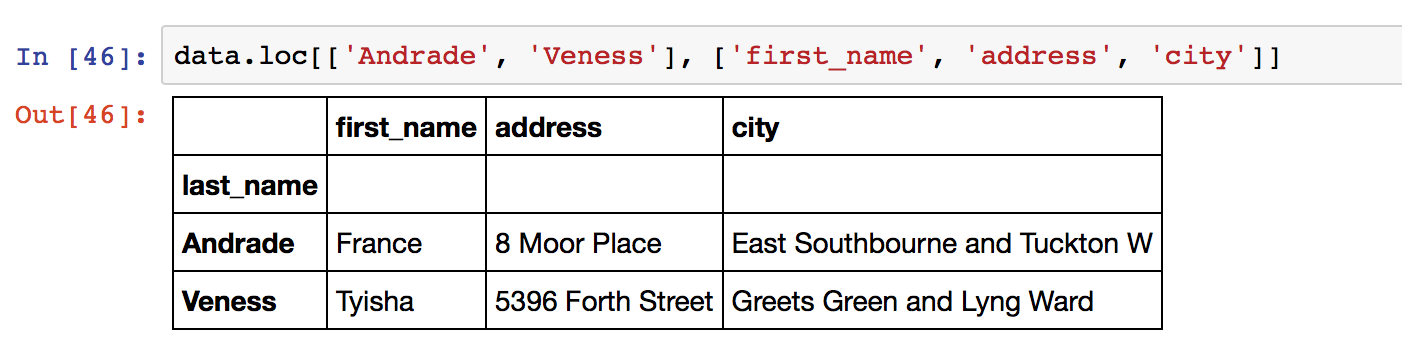
You can select ranges of index labels – the selection </code>data.loc[‘Bruch’:’Julio’]</code> will return all rows in the data frame between the index entries for “Bruch” and “Julio”. The following examples should now make sense:
Note that in the last example, data.loc[487] (the row with index value 487) is not equal to data.iloc[487] (the 487th row in the data). The index of the DataFrame can be out of numeric order, and/or a string or multi-value.
2b. Pandas Loc Boolean / Logical indexing
Conditional selections with boolean arrays using data.loc[<selection>] is the most common method that I use with Pandas DataFrames. With boolean indexing or logical selection, you pass an array or Series of True/False values to the .loc indexer to select the rows where your Series has True values.
In most use cases, you will make selections based on the values of different columns in your data set.
For example, the statement data[‘first_name’] == ‘Antonio’] produces a Pandas Series with a True/False value for every row in the ‘data’ DataFrame, where there are “True” values for the rows where the first_name is “Antonio”. These type of boolean arrays can be passed directly to the .loc indexer as so:
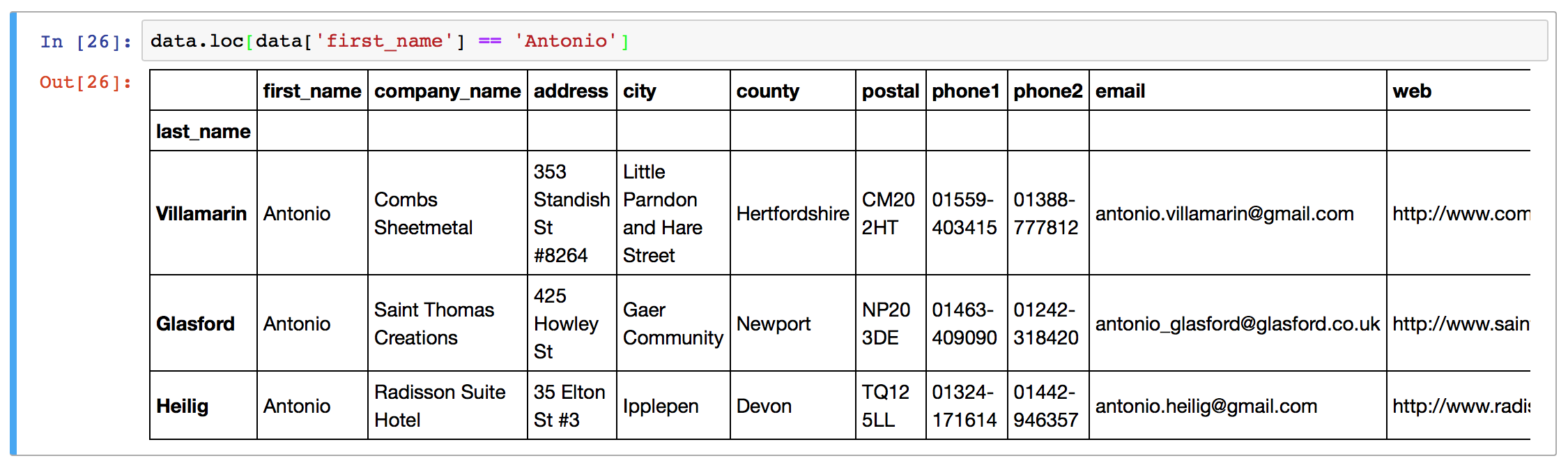
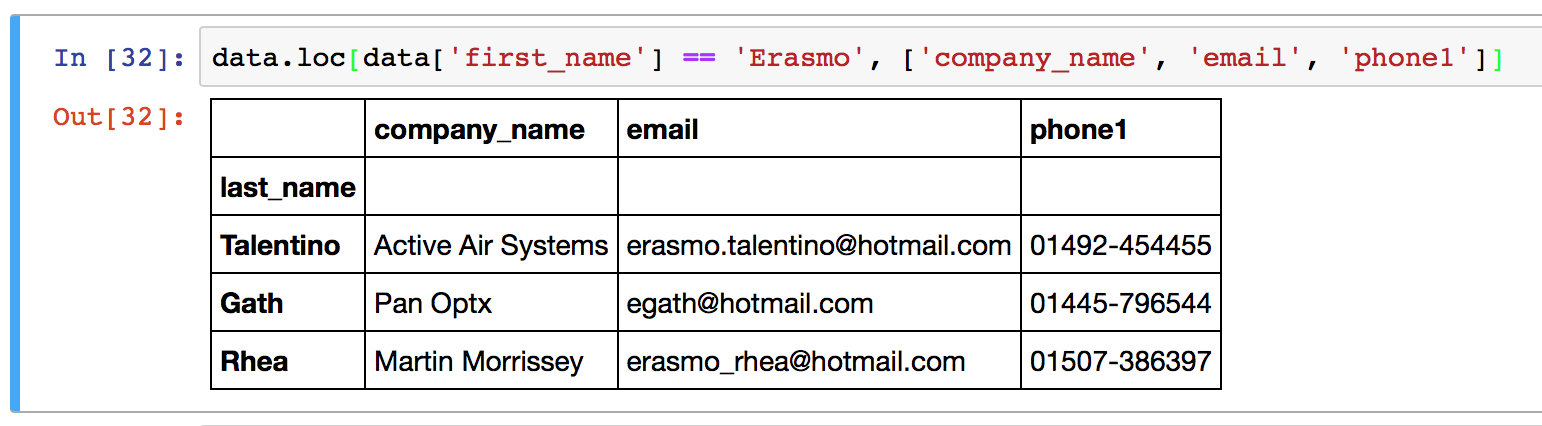
As before, a second argument can be passed to .loc to select particular columns out of the data frame. Again, columns are referred to by name for the loc indexer and can be a single string, a list of columns, or a slice “:” operation.
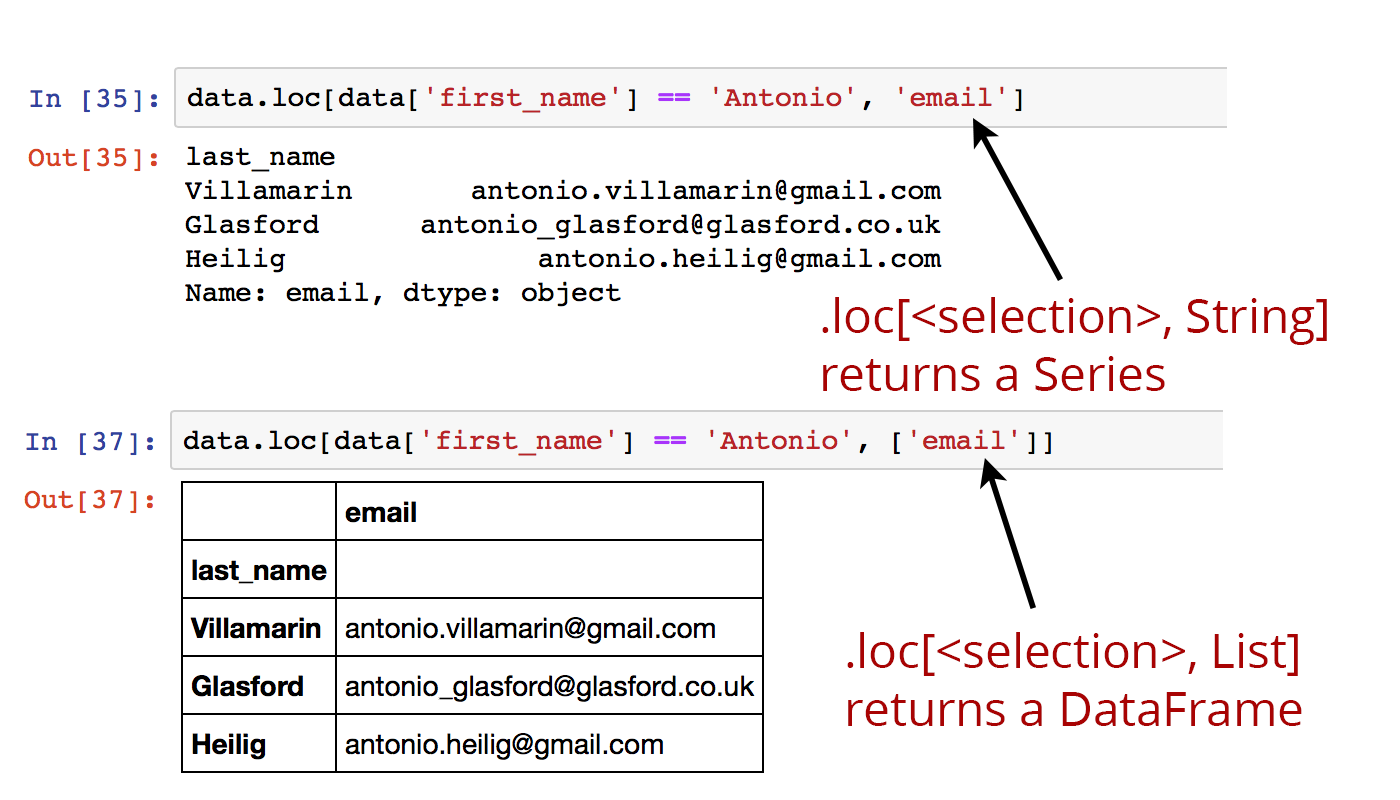
Note that when selecting columns, if one column only is selected, the .loc operator returns a Series. For a single column DataFrame, use a one-element list to keep the DataFrame format, for example:
Make sure you understand the following additional examples of .loc selections for clarity:
Logical selections and boolean Series can also be passed to the generic [] indexer of a pandas DataFrame and will give the same results: data.loc[data[‘id’] == 9] == data[data[‘id’] == 9] .
3. Selecting pandas data using ix
Note: The ix indexer has been deprecated in recent versions of Pandas, starting with version 0.20.1.
The ix[] indexer is a hybrid of .loc and .iloc. Generally, ix is label based and acts just as the .loc indexer. However, .ix also supports integer type selections (as in .iloc) where passed an integer. This only works where the index of the DataFrame is not integer based. ix will accept any of the inputs of .loc and .iloc.
Slightly more complex, I prefer to explicitly use .iloc and .loc to avoid unexpected results.
As an example:
Setting values in DataFrames using .loc
With a slight change of syntax, you can actually update your DataFrame in the same statement as you select and filter using .loc indexer. This particular pattern allows you to update values in columns depending on different conditions. The setting operation does not make a copy of the data frame, but edits the original data.
As an example:
That’s the basics of indexing and selecting with Pandas. If you’re looking for more, take a look at the .iat, and .at operations for some more performance-enhanced value accessors in the Pandas Documentation and take a look at selecting by callable functions for more iloc and loc fun.
[…] maggiori informazioni, si veda il seguente articolo (solo in […]
Really helpful Shane for beginners. Very through and detailed. Looking for more of your blogs on pandas and python.
Very helpful content, Shane. Helped me clear my understanding of working with row selections.
Thank you so much! This is very helpful and illustrative 🙂
Very precise and clear. Easy to understand. Thanks for the content
Very detailed explanation! thanks!
when following your examples, i was expecting to get a type = dataframe for the below query: however its throwing an error
print(df.iloc[[1:4, 2:4]])
excellent explanations. really helpful
Thank you so much!. Very detailed and helpful
Finally, I have a clear picture. Your instructions are precise and self-explanatory. I wish you publish a detailed book on Python Programming so that it will be of immense help for learners and programmers.
[…] You can read more about the usage of iloc here. […]
Excellent post. Thank you so much for coming with such awesome content
Thank you so much, it helped me a lot to understand pandas selection, great article for beginners like me 🙂
Thanks for the content/
Great job – even greater examples
this is so concise and fully side of selecting element in pandas. Thank you, writer!
Thank you for the explanation
Fantastic explanation. Thanks, Shane!
Exactly what I needed,n this is extremelyhelpful -thank you.
Hello!
Thank you very much for this nice article.
I try to use a dataset with scikit-learn M/L algorithm. I have approximatly 4000 samples (Sn), but my dataset is in this format : (first image, multiple lines for one output); I would like to move it in this format (second image), to have each sample on 1 raw.
loc and iloc can helps me in moving every 5 raw for column 1 in a single raw please?
Thank you for your help and advises.
Hello!
Thank you very much for this nice article.
I try to use a dataset with scikit-learn M/L algorithm. I have approximatly 4000 samples (Sn), but my dataset is in this format : (multiple lines of input for one output); I would like to move it in this format (second image), to have each sample on 1 raw.
loc and iloc can helps me in moving every 5 raw for column 1 in a single raw please?
Thank you for your help and advises.
It is the best narrative… I really mean it.
Thanks!
Thank you so much. Really helpful
Thank you so much. I needed to select a column in pandas trought .iloc[:,0]. Very good job.
In a twist, data selection is harder when there are so many ways to do it!! 🙂 I’m glad the post helped.
Thank you for your post. Very didadict and well explained.
[…] La Source Étiquettespython […]
[…] Kaynak python python […]
Best understandable explanation I have found over many, many, many searches.
thank you a lot, that was helpful. I appreciate.
Thanks! very well explained!