
This post follows on from the previous “Get Busy with Word Embeddings” post, and provides code samples and methods for you to use and create Word Embeddings / Word Vectors with your systems in Python.
To use word embeddings, you have two primary options:
- Use pre-trained models that you can download online (easiest)
- Train custom models using your own data and the Word2Vec (or another) algorithm (harder, but maybe better!).
Two Python natural language processing (NLP) libraries are mentioned here:
- Spacy is a natural language processing (NLP) library for Python designed to have fast performance, and with word embedding models built in, it’s perfect for a quick and easy start.
- Gensim is a topic modelling library for Python that provides access to Word2Vec and other word embedding algorithms for training, and it also allows pre-trained word embeddings that you can download from the internet to be loaded.
In this post, we examine how to load pre-trained models first, and then provide a tutorial for creating your own word embeddings using Gensim and the 20_newsgroups dataset.
Pre-trained Word Embeddings
Pre-trained models are the simplest way to start working with word embeddings. A pre-trained model is a set of word embeddings that have been created elsewhere that you simply load onto your computer and into memory.
The advantage of these models is that they can leverage massive datasets that you may not have access to, built using billions of different words, with a vast corpus of language that captures word meanings in a statistically robust manner. Example training data sets include the entire corpus of wikipedia text, the common crawl dataset, or the Google News Dataset. Using a pre-trained model removes the need for you to spend time obtaining, cleaning, and processing (intensively) such large datasets.
Pre-trained models are also available in languages other than English, opening up multi-lingual opportunities for your applications.
The disadvantage of pre-trained word embeddings is that the words contained within may not capture the peculiarities of language in your specific application domain. For example, Wikipedia may not have great word exposure to particular aspects of legal doctrine or religious text, so if your application is specific to a domain like this, your results may not be optimal due to the generality of the downloaded model’s word embeddings.
Pre-trained models in Spacy
Using pre-trained models in Spacy is incredible convenient, given that they come built in. Simply download the core English model using:
# run this from a normal command line python -m spacy download en_core_web_md
Spacy has a number of different models of different sizes available for use, with models in 7 different languages (include English, Polish, German, Spanish, Portuguese, French, Italian, and Dutch), and of different sizes to suit your requirements. The code snippet above installs the larger-than-standard en_core_web_md library, which includes 20k unique vectors with 300 dimensions.
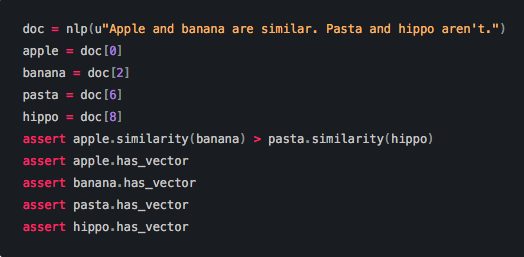
Use the vectors in Spacy by first loading the model, and then processing text (see below):
import spacy
# Load the spacy model that you have installed
nlp = spacy.load('en_core_web_md')
# process a sentence using the model
doc = nlp("This is some text that I am processing with Spacy")
# It's that simple - all of the vectors and words are assigned after this point
# Get the vector for 'text':
doc[3].vector
# Get the mean vector for the entire sentence (useful for sentence classification etc.)
doc.vector
The vectors can be accessed directly using the .vector attribute of each processed token (word). The mean vector for the entire sentence is also calculated simply using .vector, providing a very convenient input for machine learning models based on sentences.

Pre-trained models in Gensim
Gensim doesn’t come with the same in built models as Spacy, so to load a pre-trained model into Gensim, you first need to find and download one. This post on Ahogrammers’s blog provides a list of pertained models that can be downloaded and used.
A popular pre-trained option is the Google News dataset model, containing 300-dimensional embeddings for 3 millions words and phrases. Download the binary file ‘GoogleNews-vectors-negative300.bin’ (1.3 GB compressed) from https://code.google.com/archive/p/word2vec/.
Loading and accessing vectors is then straightforward:
from gensim.models import KeyedVectors
# Load vectors directly from the file
model = KeyedVectors.load_word2vec_format('data/GoogleGoogleNews-vectors-negative300.bin', binary=True)
# Access vectors for specific words with a keyed lookup:
vector = model['easy']
# see the shape of the vector (300,)
vector.shape
# Processing sentences is not as simple as with Spacy:
vectors = [model[x] for x in "This is some text I am processing with Spacy".split(' ')]
Gensim includes functions to explore the vectors loaded, examine word similarity, and to find synonyms in of words using ‘similar’ vectors:

Create Custom Word Embeddings
Training your own word embeddings need not be daunting, and, for specific problem domains, will lead to enhanced performance over pre-trained models. The Gensim library provides a simple API to the Google word2vec algorithm which is a go-to algorithm for beginners.
To train your own model, the main challenge is getting access to a training data set. Computation is not massively onerous – you’ll manage to process a large model on a powerful laptop in hours rather than days.
In this tutorial, we will train a Word2Vec model based on the 20_newsgroups data set which contains approximately 20,000 posts distributed across 20 different topics. The simplicity of the Gensim Word2Vec training process is demonstrated in the code snippets below.
Training the model in Gensim requires the input data in a list of sentences, with each sentence being a list of words, for example:
input_data = [['This', 'is', 'sentence', 'one'], ['And', 'this', 'is', 'sentence', 'two']]
As such, our initial efforts will be in cleansing and formatting the data to suit this form.
Preparing 20 Newsgroups Data
Once the newsgroups archive is extracted into a folder, there are some cleaning and extraction steps taken to get data into the input form and then training the model:
# Import libraries to build Word2Vec model, and load Newsgroups data import os import sys import re from gensim.models import Word2Vec from gensim.models.phrases import Phraser, Phrases TEXT_DATA_DIR = './data/20_newsgroup/'
# Newsgroups data is split between many files and folders.
# Directory stucture 20_newsgroup/<newsgroup label>/<post ID>
texts = [] # list of text samples
labels_index = {} # dictionary mapping label name to numeric id
labels = [] # list of label ids
label_text = [] # list of label texts
# Go through each directory
for name in sorted(os.listdir(TEXT_DATA_DIR)):
path = os.path.join(TEXT_DATA_DIR, name)
if os.path.isdir(path):
label_id = len(labels_index)
labels_index[name] = label_id
for fname in sorted(os.listdir(path)):
# News groups posts are named as numbers, with no extensions.
if fname.isdigit():
fpath = os.path.join(path, fname)
f = open(fpath, encoding='latin-1')
t = f.read()
i = t.find('\n\n') # skip header in file (starts with two newlines.)
if 0 < i:
t = t[i:]
texts.append(t)
f.close()
labels.append(label_id)
label_text.append(name)
print('Found %s texts.' % len(texts))
# >> Found 1997 texts.
The data is loaded into memory (a single list ‘texts’) at this point; for preprocessing, remove all punctuation, and excess information.
# Cleaning data - remove punctuation from every newsgroup text
sentences = []
# Go through each text in turn
for ii in range(len(texts)):
sentences = [re.sub(pattern=r'[\!"#$%&\*+,-./:;<=>?@^_`()|~=]',
repl='',
string=x
).strip().split(' ') for x in texts[ii].split('\n')
if not x.endswith('writes:')]
sentences = [x for x in sentences if x != ['']]
texts[ii] = sentences
Each original document is now represented in the list, ‘texts’, as a list of sentences, and each sentence is a list of words.
Finally, combine all of the sentences from every document into a single list of sentences.
# concatenate all sentences from all texts into a single list of sentences
all_sentences = []
for text in texts:
all_sentences += text
Phrase Detection using Gensim Phraser
Commonly occurring multiword expressions (bigrams / trigrams) in text carry different meaning to the words occurring singularly. For example, the words ‘new’ and ‘York’ expressed singularly are inherently different to the utterance ‘New York’. Detecting frequently co-occuring words and combining them can enhance word vector accuracy.
A ‘Phraser‘ from Gensim can detect frequently occurring bigrams easily, and apply a transform to data to create pairs, i.e. ‘New York’ -> ‘New_York’. Pre-processing text input to account for such bigrams can improve the accuracy and usefulness of the resulting word vectors. Ultimately, instead of training vectors for ‘new’ and ‘york’ separately, a new vector for ‘New_York’ is created.
The gensim.models.phrases module provides everything required in a simple form:
# Phrase Detection # Give some common terms that can be ignored in phrase detection # For example, 'state_of_affairs' will be detected because 'of' is provided here: common_terms = ["of", "with", "without", "and", "or", "the", "a"] # Create the relevant phrases from the list of sentences: phrases = Phrases(all_sentences, common_terms=common_terms) # The Phraser object is used from now on to transform sentences bigram = Phraser(phrases) # Applying the Phraser to transform our sentences is simply all_sentences = list(bigram[all_sentences])
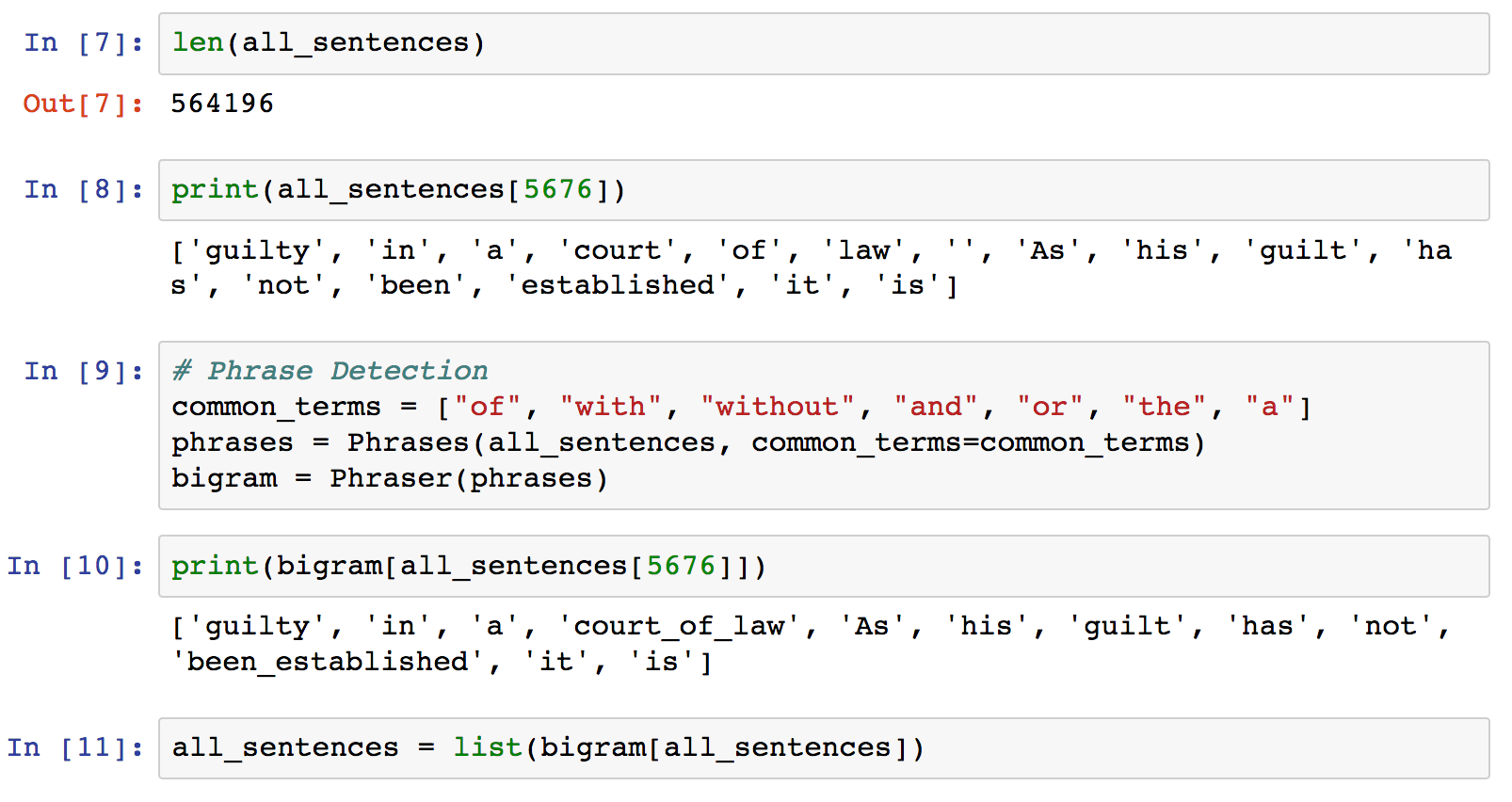
The Gensim Phraser process can be repeated to detect trigrams (groups of three words that co-occur) and more by training a second Phraser object on the already processed data. (see gensim docs). The parameters are tuneable to include or exclude terms based on their frequency, and should be fine tuned. In the example above, ‘court_of_law’ is a good example phrase, whereas ‘been_established’ may indicate an overly greedy application of the phrase detection algorithm.
Creating the Word Embeddings using Word2Vec
The final step, once data has been preprocessed and cleaned is creating the word vectors.
model = Word2Vec(all_sentences,
min_count=3, # Ignore words that appear less than this
size=200, # Dimensionality of word embeddings
workers=2, # Number of processors (parallelisation)
window=5, # Context window for words during training
iter=30) # Number of epochs training over corpus
This example, with only 564k sentences, is a toy example, and the resulting word embeddings would not be expected to be as useful as those trained by Google / Facebook on larger corpus’ of training data.
In total, the 20_newsgroups dataset provided 80,167 different words for our model, and, even with the smaller data set, relationships between words can be observed.
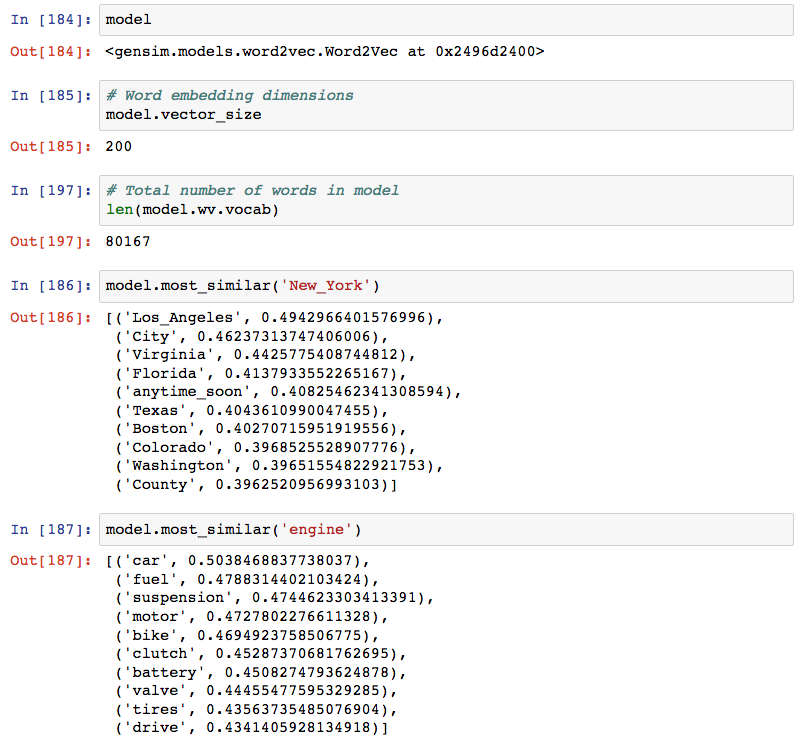
There are a range of tuneable parameters for the Word2Vec algorithm provided by Gensim to assist in achieving the desired result.
For larger data sets, training time will be much longer, and memory can be an issue if all of the training data is loaded as in our example above. The Rare Technologies blog provides some useful information for formatting input data as an iterable, reducing memory footprint during the training process, and also in methods for evaluating word vector and performance after training.
Once trained, you can access the newly encoded word vectors in the same way as for pretrained models, and use the outputs in any of your text classification or visualisation tasks.
In addition to Word2Vec, Gensim also includes algorithms for fasttext, VarEmbed, and WordRank (original) also.
Conclusion
Ideally, this post will have given enough information to start working in Python with Word embeddings, whether you intend to use off-the-shelf models or models based on your own data sets.
A third option exists, which is to take an off-the-shelf model, and then ‘continue’ the training using Gensim, but with your own application-specific data and vocabulary, also mentioned on the Rare Technologies blog.
For further, and useful reading on these topics, please see:
- My introductory post on Word Embeddings.
- Rare Technologies blog post on training without heavy RAM usage, and evaluation of model.
- Word Vector Tutorial from Machine Learning Mastery that includes some useful visualisation techniques for the resulting model.
- Tutorial from Kavita Ganesan training word embeddings on review data.
@Shane, great post on a hot topic!
You guys are so lucky working with an English corpus!
If you change the language, it all gets exponentially more complicated:
– To my knowledge, you can’t train GloVe with your own corpus.
– Word2Vec is easily trained with Gensim, but everything else is not easy 🙂
– Word2Vec needs a huge corpus. My guess is >500MB
My personal conclusion for non-English word modeling:
– stick to BoW (bi-gram). Unless you’re a monster tech firm, BoW (bi-gram) works surprisingly well.
PS: for those into Deep Learning + Natural Language Processing, check out prodi.gy (from the makers of SpaCy). Prodi.gy enables you to manually label sentences efficiently.
Even for those who are working with non English ?
[…] References 1. spaCY 2. Word Embeddings in Python with Spacy and Gensim […]
If I want to use this trained gensim model in spacy, how is it possible?
[…] https://www.shanelynn.ie/word-embeddings-in-python-with-spacy-and-gensim/ […]
[…] https://www.shanelynn.ie/word-embeddings-in-python-with-spacy-and-gensim/ […]
What if I want to find the similar words of a word.For example: If someone says banking domain and other says financial domain,then these both belongs to the same topic.So how to understand any word related to a heading, like I’ve given in above example.
Hi Pal, I’d recommend looking at word similarity / phrase similarity in gensim, and then also looking into the topic-modelling techniques that are available, e.g. LDA (Latent Dirichelet Allocation).
[…] Word Embeddings in Python with Spacy and Gensim […]