Pandas – Python Data Analysis Library
I’ve recently started using Python’s excellent Pandas library as a data analysis tool, and, while finding the transition from R’s excellent data.table library frustrating at times, I’m finding my way around and finding most things work quite well.
One aspect that I’ve recently been exploring is the task of grouping large data frames by different variables, and applying summary functions on each group. This is accomplished in Pandas using the “groupby()” and “agg()” functions of Panda’s DataFrame objects.
Update: Pandas version 0.20.1 in May 2017 changed the aggregation and grouping APIs. This post has been updated to reflect the new changes.
A Sample DataFrame

In order to demonstrate the effectiveness and simplicity of the grouping commands, we will need some data. For an example dataset, I have extracted my own mobile phone usage records. I analysed this type of data using Pandas during my work on KillBiller. If you’d like to follow along – the full csv file is available here.
The dataset contains 830 entries from my mobile phone log spanning a total time of 5 months. The CSV file can be loaded into a pandas DataFrame using the pandas.DataFrame.from_csv() function, and looks like this:
| date | duration | item | month | network | network_type | |
|---|---|---|---|---|---|---|
| 0 | 15/10/14 06:58 | 34.429 | data | 2014-11 | data | data |
| 1 | 15/10/14 06:58 | 13.000 | call | 2014-11 | Vodafone | mobile |
| 2 | 15/10/14 14:46 | 23.000 | call | 2014-11 | Meteor | mobile |
| 3 | 15/10/14 14:48 | 4.000 | call | 2014-11 | Tesco | mobile |
| 4 | 15/10/14 17:27 | 4.000 | call | 2014-11 | Tesco | mobile |
| 5 | 15/10/14 18:55 | 4.000 | call | 2014-11 | Tesco | mobile |
| 6 | 16/10/14 06:58 | 34.429 | data | 2014-11 | data | data |
| 7 | 16/10/14 15:01 | 602.000 | call | 2014-11 | Three | mobile |
| 8 | 16/10/14 15:12 | 1050.000 | call | 2014-11 | Three | mobile |
| 9 | 16/10/14 15:30 | 19.000 | call | 2014-11 | voicemail | voicemail |
| 10 | 16/10/14 16:21 | 1183.000 | call | 2014-11 | Three | mobile |
| 11 | 16/10/14 22:18 | 1.000 | sms | 2014-11 | Meteor | mobile |
| … | … | … | … | … | … | … |
The main columns in the file are:
- date: The date and time of the entry
- duration: The duration (in seconds) for each call, the amount of data (in MB) for each data entry, and the number of texts sent (usually 1) for each sms entry.
- item: A description of the event occurring – can be one of call, sms, or data.
- month: The billing month that each entry belongs to – of form ‘YYYY-MM’.
- network: The mobile network that was called/texted for each entry.
- network_type: Whether the number being called was a mobile, international (‘world’), voicemail, landline, or other (‘special’) number.
Phone numbers were removed for privacy. The date column can be parsed using the extremely handy dateutil library.
import pandas as pd
import dateutil
# Load data from csv file
data = pd.DataFrame.from_csv('phone_data.csv')
# Convert date from string to date times
data['date'] = data['date'].apply(dateutil.parser.parse, dayfirst=True)
Summarising the DataFrame
Once the data has been loaded into Python, Pandas makes the calculation of different statistics very simple. For example, mean, max, min, standard deviations and more for columns are easily calculable:
# How many rows the dataset data['item'].count() Out[38]: 830 # What was the longest phone call / data entry? data['duration'].max() Out[39]: 10528.0 # How many seconds of phone calls are recorded in total? data['duration'][data['item'] == 'call'].sum() Out[40]: 92321.0 # How many entries are there for each month? data['month'].value_counts() Out[41]: 2014-11 230 2015-01 205 2014-12 157 2015-02 137 2015-03 101 dtype: int64 # Number of non-null unique network entries data['network'].nunique() Out[42]: 9
The need for custom functions is minimal unless you have very specific requirements. The full range of basic statistics that are quickly calculable and built into the base Pandas package are:
| Function | Description |
|---|---|
| count | Number of non-null observations |
| sum | Sum of values |
| mean | Mean of values |
| mad | Mean absolute deviation |
| median | Arithmetic median of values |
| min | Minimum |
| max | Maximum |
| mode | Mode |
| abs | Absolute Value |
| prod | Product of values |
| std | Unbiased standard deviation |
| var | Unbiased variance |
| sem | Unbiased standard error of the mean |
| skew | Unbiased skewness (3rd moment) |
| kurt | Unbiased kurtosis (4th moment) |
| quantile | Sample quantile (value at %) |
| cumsum | Cumulative sum |
| cumprod | Cumulative product |
| cummax | Cumulative maximum |
| cummin | Cumulative minimum |
The .describe() function is a useful summarisation tool that will quickly display statistics for any variable or group it is applied to. The describe() output varies depending on whether you apply it to a numeric or character column.
Summarising Groups in the DataFrame
There’s further power put into your hands by mastering the Pandas “groupby()” functionality. Groupby essentially splits the data into different groups depending on a variable of your choice. For example, the expression data.groupby(‘month’) will split our current DataFrame by month.
The groupby() function returns a GroupBy object, but essentially describes how the rows of the original data set has been split. the GroupBy object .groups variable is a dictionary whose keys are the computed unique groups and corresponding values being the axis labels belonging to each group. For example:
data.groupby(['month']).groups.keys() Out[59]: ['2014-12', '2014-11', '2015-02', '2015-03', '2015-01'] len(data.groupby(['month']).groups['2014-11']) Out[61]: 230
Functions like max(), min(), mean(), first(), last() can be quickly applied to the GroupBy object to obtain summary statistics for each group – an immensely useful function. This functionality is similar to the dplyr and plyr libraries for R. Different variables can be excluded / included from each summary requirement.
# Get the first entry for each month
data.groupby('month').first()
Out[69]:
date duration item network network_type
month
2014-11 2014-10-15 06:58:00 34.429 data data data
2014-12 2014-11-13 06:58:00 34.429 data data data
2015-01 2014-12-13 06:58:00 34.429 data data data
2015-02 2015-01-13 06:58:00 34.429 data data data
2015-03 2015-02-12 20:15:00 69.000 call landline landline
# Get the sum of the durations per month
data.groupby('month')['duration'].sum()
Out[70]:
month
2014-11 26639.441
2014-12 14641.870
2015-01 18223.299
2015-02 15522.299
2015-03 22750.441
Name: duration, dtype: float64
# Get the number of dates / entries in each month
data.groupby('month')['date'].count()
Out[74]:
month
2014-11 230
2014-12 157
2015-01 205
2015-02 137
2015-03 101
Name: date, dtype: int64
# What is the sum of durations, for calls only, to each network
data[data['item'] == 'call'].groupby('network')['duration'].sum()
Out[78]:
network
Meteor 7200
Tesco 13828
Three 36464
Vodafone 14621
landline 18433
voicemail 1775
Name: duration, dtype: float64
You can also group by more than one variable, allowing more complex queries.
# How many calls, sms, and data entries are in each month?
data.groupby(['month', 'item'])['date'].count()
Out[76]:
month item
2014-11 call 107
data 29
sms 94
2014-12 call 79
data 30
sms 48
2015-01 call 88
data 31
sms 86
2015-02 call 67
data 31
sms 39
2015-03 call 47
data 29
sms 25
Name: date, dtype: int64
# How many calls, texts, and data are sent per month, split by network_type?
data.groupby(['month', 'network_type'])['date'].count()
Out[82]:
month network_type
2014-11 data 29
landline 5
mobile 189
special 1
voicemail 6
2014-12 data 30
landline 7
mobile 108
voicemail 8
world 4
2015-01 data 31
landline 11
mobile 160
....
Groupby output format – Series or DataFrame?
The output from a groupby and aggregation operation varies between Pandas Series and Pandas Dataframes, which can be confusing for new users. As a rule of thumb, if you calculate more than one column of results, your result will be a Dataframe. For a single column of results, the agg function, by default, will produce a Series.
You can change this by selecting your operation column differently:
# produces Pandas Series
data.groupby('month')['duration'].sum()
# Produces Pandas DataFrame
data.groupby('month')[['duration']].sum()
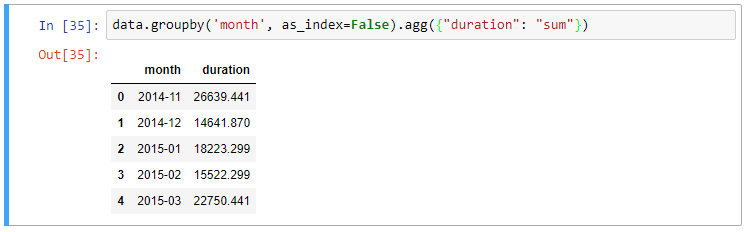
The groupby output will have an index or multi-index on rows corresponding to your chosen grouping variables. To avoid setting this index, pass “as_index=False” to the groupby operation.
data.groupby('month', as_index=False).agg({"duration": "sum"})
Multiple Statistics per Group
The final piece of syntax that we’ll examine is the “agg()” function for Pandas. The aggregation functionality provided by the agg() function allows multiple statistics to be calculated per group in one calculation.
Applying a single function to columns in groups
Instructions for aggregation are provided in the form of a python dictionary or list. The dictionary keys are used to specify the columns upon which you’d like to perform operations, and the dictionary values to specify the function to run.
For example:
# Group the data frame by month and item and extract a number of stats from each group
data.groupby(
['month', 'item']
).agg(
{
'duration':sum, # Sum duration per group
'network_type': "count", # get the count of networks
'date': 'first' # get the first date per group
}
)
The aggregation dictionary syntax is flexible and can be defined before the operation. You can also define functions inline using “lambda” functions to extract statistics that are not provided by the built-in options.
# Define the aggregation procedure outside of the groupby operation
aggregations = {
'duration':'sum',
'date': lambda x: max(x) - 1
}
data.groupby('month').agg(aggregations)
Applying multiple functions to columns in groups
To apply multiple functions to a single column in your grouped data, expand the syntax above to pass in a list of functions as the value in your aggregation dataframe. See below:
# Group the data frame by month and item and extract a number of stats from each group
data.groupby(
['month', 'item']
).agg(
{
# Find the min, max, and sum of the duration column
'duration': [min, max, sum],
# find the number of network type entries
'network_type': "count",
# minimum, first, and number of unique dates
'date': [min, 'first', 'nunique']
}
)
The agg(..) syntax is flexible and simple to use. Remember that you can pass in custom and lambda functions to your list of aggregated calculations, and each will be passed the values from the column in your grouped data.
Renaming grouped aggregation columns
We’ll examine two methods to group Dataframes and rename the column results in your work.

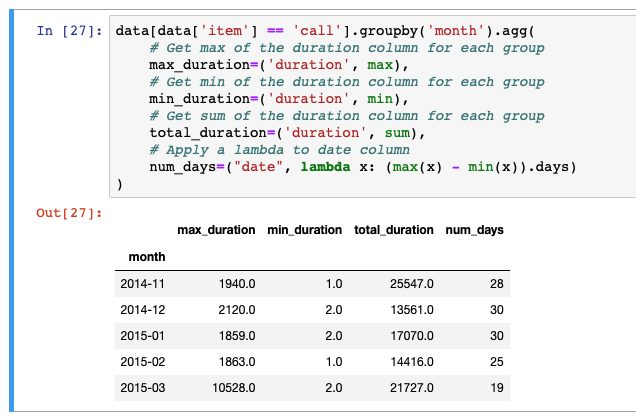
Recommended: Tuple Named Aggregations
Introduced in Pandas 0.25.0, groupby aggregation with relabelling is supported using “named aggregation” with simple tuples. Python tuples are used to provide the column name on which to work on, along with the function to apply.
For example:
data[data['item'] == 'call'].groupby('month').agg(
# Get max of the duration column for each group
max_duration=('duration', max),
# Get min of the duration column for each group
min_duration=('duration', min),
# Get sum of the duration column for each group
total_duration=('duration', sum),
# Apply a lambda to date column
num_days=("date", lambda x: (max(x) - min(x)).days)
)
For clearer naming, Pandas also provides the NamedAggregation named-tuple, which can be used to achieve the same as normal tuples:
data[data['item'] == 'call'].groupby('month').agg(
max_duration=pd.NamedAgg(column='duration', aggfunc=max),
min_duration=pd.NamedAgg(column='duration', aggfunc=min),
total_duration=pd.NamedAgg(column='duration', aggfunc=sum),
num_days=pd.NamedAgg(
column="date",
aggfunc=lambda x: (max(x) - min(x)).days)
)
Note that in versions of Pandas after release, applying lambda functions only works for these named aggregations when they are the only function applied to a single column, otherwise causing a KeyError.
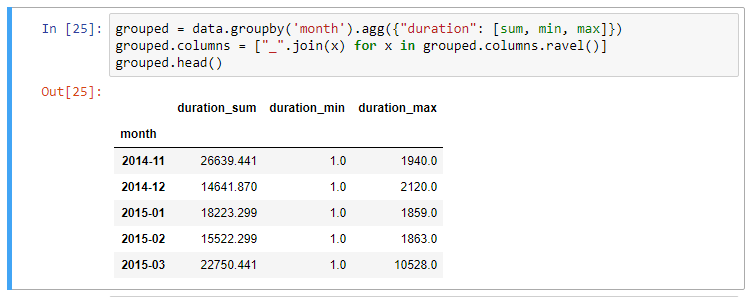
Renaming index using droplevel and ravel
When multiple statistics are calculated on columns, the resulting dataframe will have a multi-index set on the column axis. The multi-index can be difficult to work with, and I typically have to rename columns after a groupby operation.
One option is to drop the top level (using .droplevel) of the newly created multi-index on columns using:
grouped = data.groupby('month').agg("duration": [min, max, mean])
grouped.columns = grouped.columns.droplevel(level=0)
grouped.rename(columns={
"min": "min_duration", "max": "max_duration", "mean": "mean_duration"
})
grouped.head()
However, this approach loses the original column names, leaving only the function names as column headers. A neater approach, as suggested to me by a reader, is using the ravel() method on the grouped columns. Ravel() turns a Pandas multi-index into a simpler array, which we can combine into sensible column names:
grouped = data.groupby('month').agg("duration": [min, max, mean])
# Using ravel, and a string join, we can create better names for the columns:
grouped.columns = ["_".join(x) for x in grouped.columns.ravel()]
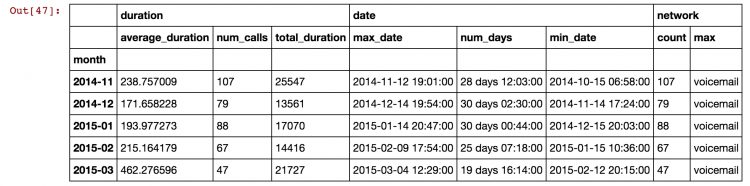
Dictionary groupby format <DEPRECATED>
There were substantial changes to the Pandas aggregation function in May of 2017. Renaming of variables using dictionaries within the agg() function as in the diagram below is being deprecated/removed from Pandas – see notes.

In older Pandas releases (< 0.20.1), renaming the newly calculated columns was possible through nested dictionaries, or by passing a list of functions for a column. Our final example calculates multiple values from the duration column and names the results appropriately. Note that the results have multi-indexed column headers.
Note this syntax will no longer work for new installations of Python Pandas.
# Define the aggregation calculations
aggregations = {
# work on the "duration" column
'duration': {
# get the sum, and call this result 'total_duration'
'total_duration': 'sum',
# get mean, call result 'average_duration'
'average_duration': 'mean',
'num_calls': 'count'
},
# Now work on the "date" column
'date': {
# Find the max, call the result "max_date"
'max_date': 'max',
'min_date': 'min',
# Calculate the date range per group
'num_days': lambda x: max(x) - min(x)
},
# Calculate two results for the 'network' column with a list
'network': ["count", "max"]
}
# Perform groupby aggregation by "month",
# but only on the rows that are of type "call"
data[data['item'] == 'call'].groupby('month').agg(aggregations)
Summary of Python Pandas Grouping
The groupby functionality in Pandas is well documented in the official docs and performs at speeds on a par (unless you have massive data and are picky with your milliseconds) with R’s data.table and dplyr libraries.
If you are interested in another example for practice, I used these same techniques to analyse weather data for this post, and I’ve put “how-to” instructions here.
There are plenty of resources online on this functionality, and I’d recommomend really conquering this syntax if you’re using Pandas in earnest at any point.
- DataQuest Tutorial on Data Analysis: https://www.dataquest.io/blog/pandas-tutorial-python-2/
- Chris Albon notes on Groups: https://chrisalbon.com/python/pandas_apply_operations_to_groups.html
- Greg Reda Pandas Tutorial: http://www.gregreda.com/2013/10/26/working-with-pandas-dataframes/
I’m here just to thank you for this awesome reference on pandas groupby. Thanks!
Fantastic !!
Excellent explanation. This is epic.
Thought about an analysis for a month, and you helped me through it with 4 lines of code.
I am astounded. Keeeeep blogging!
Thanks for the fantastic blog!!
I have a question about finding patterns of a CSV dataset. Consider the example data set(Phone log) provided in your blog, If anyone asked to find patterns of the dataset, whats the best way to show the pattern.
Great example of groupby and multi-key .agg(). Thanks for your hard work.
Awesome Blog!!!
Thank you very much…
This helped me a lot..
I was looking for a way to perform R’s group_by() & summarise() in Pandas. This is a super helpful. Thank you!
very productive. Thank you. very much. i would like to know more about grouping. can you please provide any further readings ?
Thanks. It really helped!
That’s one small webpage for pandas, one giant leap for data analysis
As an former educator, I commend you on lucid and complete introduction to this general topic. Thank you!
There is clearer way to rename the aggregated columns result, from pandas 0.25.0
see: https://pandas.pydata.org/pandas-docs/stable/whatsnew/v0.25.0.html#groupby-aggregation-with-relabeling
in short:
In [4]: animals.groupby(“kind”).agg(
…: min_height=(‘height’, ‘min’),
…: max_height=(‘height’, ‘max’),
…: average_weight=(‘weight’, np.mean),
…: )
…:
Out[4]:
min_height max_height average_weight
kind
cat 9.1 9.5 8.90
dog 6.0 34.0 102.75
[2 rows x 3 columns]
Yes indeed – thanks. The latest changes make updating the column names a lot simpler. I’ll update the blog post to reflect this asap!
excellent blog so much easy to understand
Thanks for this blog!
Tell me, please, one thing. Do you see any advantage of using this aggregation comparing loading data to SQL and doing all aggregations and manipulations there? Aggregations joining and merge is much simpler in SQL (consider analytical functions and use of subqueries for combining). Myself, I just tend to load data to SQL, prepare data set and get it to notebooks just for actual use/graph/model run ..
Hi Alexander. In short, yes, and it probably depends on your familiarity with SQL vs Pandas Syntax. However, either way, it’s very rare that for a particular analysis, you can get away with one SQL query to get the data into a format that suits all of the questions you want to ask of it. For plotting, summarising, and exploring after loading into Python – I think that you absolutely can save time and be more efficient by performing those operations in Pandas rather than rewriting an SQL query and re-querying the database.
My typical workflow is – one big query for SQL to get the data in a semi-flat structure to load to Python, followed by tonnes of Python grouping and aggregation and plotting.
This is a fantastic explanation of using .groupby!! Thank you so much.
.value_counts() helped me a lot, thanks !
Hi, I have a question. I am using the code below as you specified to create a table. Now I want to make sure the Price only shows me data upto decimal points instead of default. How can I add the function here from np.round or something else ?
Price_by_NG =Data.groupby(
[‘neighbourhood_group’], as_index=False
).agg(
{
‘Visits’:sum,
‘price’:’mean’,
}
)
Price_by_NG
Hi Chaitanya, for this, because you are applying two functions, you will have to use a lambda function and not the “mean” as a string.
Also you’ll need to import numpy.
import numpy as np
Data.groupby(
[‘neighbourhood_group’], as_index=False
).agg(
{
‘Visits’:sum,
‘price’: lambda x: np.round(np.mean(x), 2),
}
)
Hope this helps, best of luck!
An apt explanation for using aggregate, thank you!
It was very useful to understand grouping. Thank you very much for keeping it simple and clear.
Thank you for the awesome explanation. But I do have three questions unanswered, I have googled them lots but didn’t get luck. Really appreciate if you can help me clarifying any of them if possible.
1: why some functions can work either having quote or not, like max, min, but some only work when have quotes like unique, std, first..? what makes this differences, is it bc from different modules?
2: which modules these functions belong to, some seems builtin like max, min, but what about unique, std, first, cumsum …etc?
3: There are overlap functions in pandas.core.groupby.GroupBy and pandas.core.groupby.dataframegroupby, what are the differences between them?
4: why df.groupby(“Col_A”)[“Col_B”].agg(np.std) ends as NaN for groups with single row, while np.std directly apply to single value return 0 as expected. like, np.std(10) = 0.
Thanks again,
Sincerely,
I’ve been visiting your post every now and then to review some Pandas features. Wanna say “Thank you” for your great post.
very informative
1st, thanks a mil. Bookmarked.
2nd, I’ve tried the named aggregation with simple tuples, the function name should be quoted: i.e. min_duration=(‘duration’, ‘min’), error otherwise. Pandas 1.0.3.
Shane,
I know how to do data analyses with the usual suspects as Qlik, Excel, Microsoft Power BI, but I’m fairly new at Python and stuff like Pandas. It is a steep hill to climb.
You have no idea how much your articles help me with understanding how I can do my analysis in Python, Pandas and other modules.
Thanks very much for all the work you do helping others!
Rudi
[…] Source: https://www.shanelynn.ie/summarising-aggregation-and-grouping-data-in-python-pandas/ […]
Wonderfull!!! Thanks!!
Excellent article. This just made my day or may be a week..
🙂 That’s a decent result!
Wonderful!
Thank you for the awesome explanation