

FAST TRACK: There is some python code that allows you to scrape bike availability from bike schemes at the bottom of this post…
SLOW TRACK: As a recent aside, I was interested in collecting Dublin Bikes usage data over a long time period for data visualisation and exploration purposes. The Dublinbikes scheme was launched in September 2009 and is operated by JCDeaux and the Dublin City Council and is one of the more successful public bike schemes that has been implemented. To date, there have been over 6 million journeys and over 37,000 long term subscribers to the scheme. The bike scheme has attracted considerable press recently since an expansion to 1500 bikes and 102 stations around the city.
I wanted to collect, in real time, the status of all of the Dublin Bike Stations across Dublin over a number of months, and then visualise the bike usage and journey numbers at a number of different stations. Things like this:
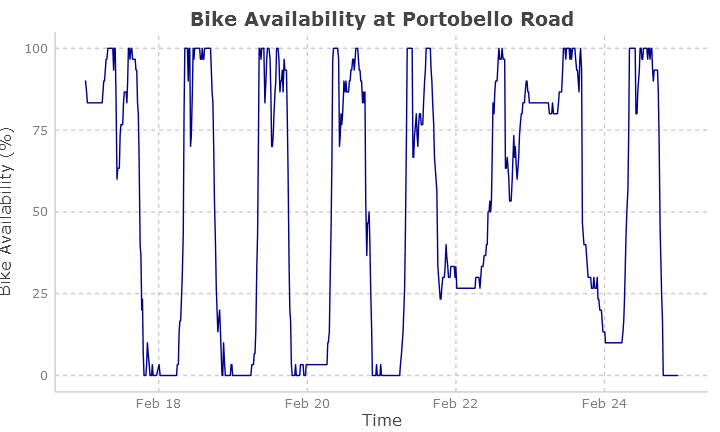
There is no official public API that allows a large number of requests without IP blocking. The slightly-hidden API at the Dublin Cyclocity website started to block me after only a few minutes of requests. However, the good people at Citybik.es provide a wonderful API that provides real-time JSON data for a host of cities in Europe, America, and Australasia.
Data Download
During this process, I scraped approximately 3.5 million entries from the Dublin Bikes website over a period of 30 days in February 2014. You can download the data for your own analysis in CSV form here, and in SQL-Lite form here. The data has columns for station name, station index/id, date and time, and number of bikes and spaces available.
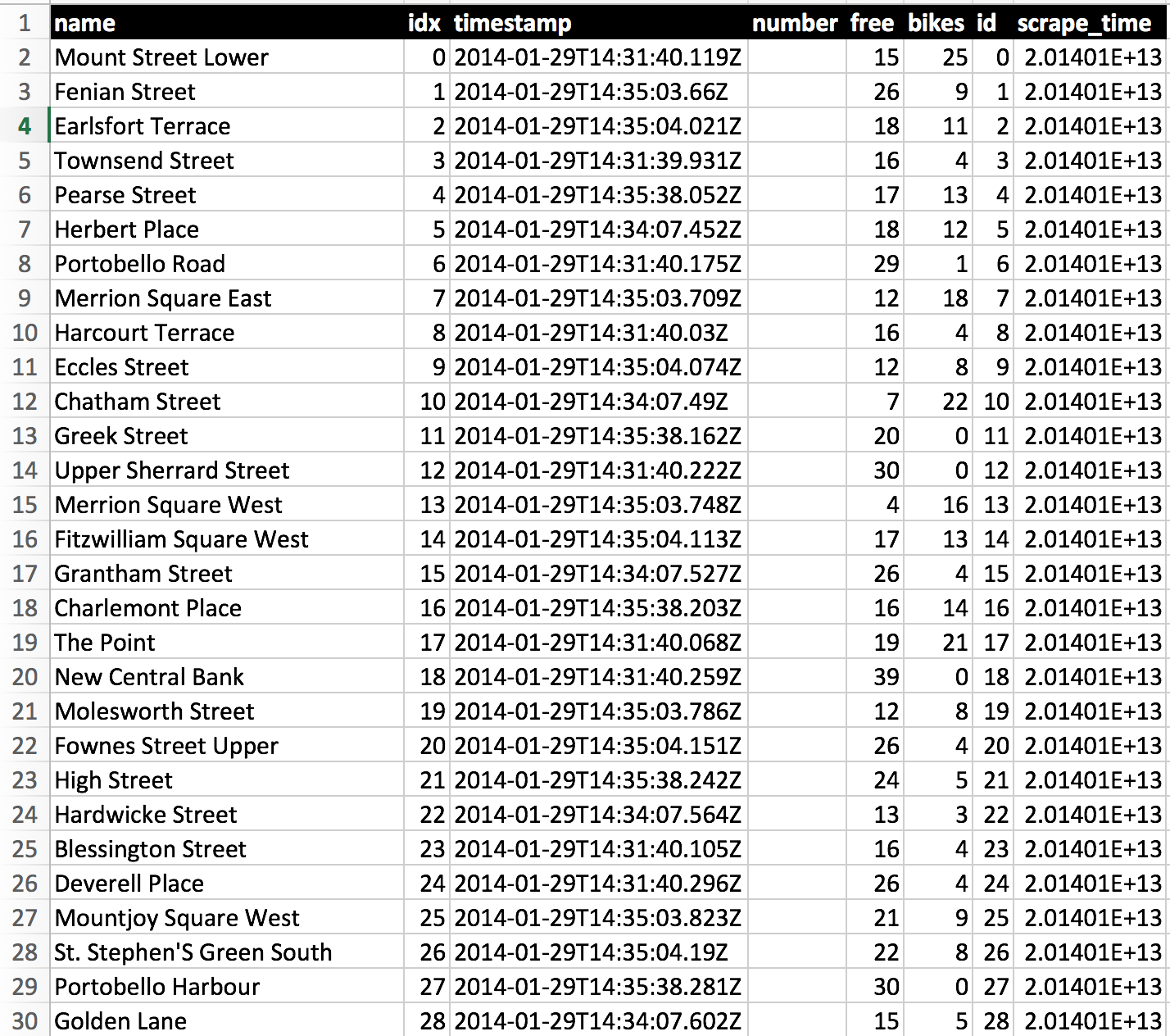
Scrape Data from Dublin Bikes
The code below provides a short and simple scraper that queries the Citybik.es API at a predefined rate and stores all of the results into a CSV or SQLite Database file. All data is returned from the API as a JSON dump detailing bike availability at all stations, this data is parsed, converted into a pandas data frame, and inserted into the requested data container. You’ll need python 2.7, and a few dependencies that are accessible using Pip or easy_install.
Maybe you’ll find it useful on your data adventures.
# Python City Bikes Scraper
#
# Simple functions to use the citybik.es API to record bike availability in a specific city.
# Settings for scrapers can be changed in lines 18-22
#
# Built using Python 2.7
#
# Shane Lynn 24/03/2014
# @shane_a_lynn
# http://104.236.88.249
import requests
import pandas as pd
import pandas.io.sql as pdsql
from time import sleep, strftime, gmtime
import json
import sqlite3
# define the city you would like to get information from here:
# for full list see http://api.citybik.es
API_URL = "http://api.citybik.es/dublinbikes.json"
#Settings:
SAMPLE_TIME = 120 # number of seconds between samples
SQLITE = False # If true - data is stored in SQLite file, if false - csv.
SQLITE_FILE = "bikedb.db" # SQLite file to save data in
CSV_FILE = "output.csv" # CSV file to save data in
def getAllStationDetails():
print "\n\nScraping at " + strftime("%Y%m%d%H%M%S", gmtime())
try:
# this url has all the details
decoder = json.JSONDecoder()
station_json = requests.get(API_URL, proxies='')
station_data = decoder.decode(station_json.content)
except:
print "---- FAIL ----"
return None
#remove unnecessary data - space saving
# we dont need latitude and longitude
for ii in range(0, len(station_data)):
del station_data[ii]['lat']
del station_data[ii]['lng']
#del station_data[ii]['station_url']
#del station_data[ii]['coordinates']
print " --- SUCCESS --- "
return station_data
def writeToCsv(data, filename="output.csv"):
"""
Take the list of results and write as csv to filename.
"""
data_frame = pd.DataFrame(data)
data_frame['time'] = strftime("%Y%m%d%H%M%S", gmtime())
data_frame.to_csv(filename, header=False, mode="a")
def writeToDb(data, db_conn):
"""
Take the list of results and write to sqlite database
"""
data_frame = pd.DataFrame(data)
data_frame['scrape_time'] = strftime("%Y%m%d%H%M%S", gmtime())
pdsql.write_frame(data_frame, "bikedata", db_conn, flavor="sqlite", if_exists="append", )
db_conn.commit()
if __name__ == "__main__":
# Create / connect to Sqlite3 database
conn = sqlite3.connect(SQLITE_FILE) # or use :memory: to put it in RAM
cursor = conn.cursor()
# create a table to store the data
cursor.execute("""CREATE TABLE IF NOT EXISTS bikedata
(name text, idx integer, timestamp text, number integer,
free integer, bikes integer, id integer, scrape_time text)
""")
conn.commit()
#run main function
# we need to run the full collection, parsing, and writing every minute.
while True:
station_data = getAllStationDetails()
if station_data:
if SQLITE:
writeToDb(station_data, conn)
else:
writeToCsv(station_data, filename=CSV_FILE)
print "Sleeping for 120 seconds."
sleep(120)
Hello, CityBikes here!
Thank’s for using our project and including it on this blog post. We’ve came to add that the relevant code to scrape the Dublin bike share website (or any JCDecaux based website not included on their official API) can be found on the following link:
https://github.com/eskerda/PyBikes/blob/experimental/pybikes/cyclocity.py#L115
Regards,
I have visited killbiller website and it’s awesome. I am also tech enthusiast and prefer to work on complex projects. One of the thing that i developed is custom web scraper using dotnet and python. Here is link to it.webdata-scraping.com/web-scraping-application-custom-scraper-development-project-demo/